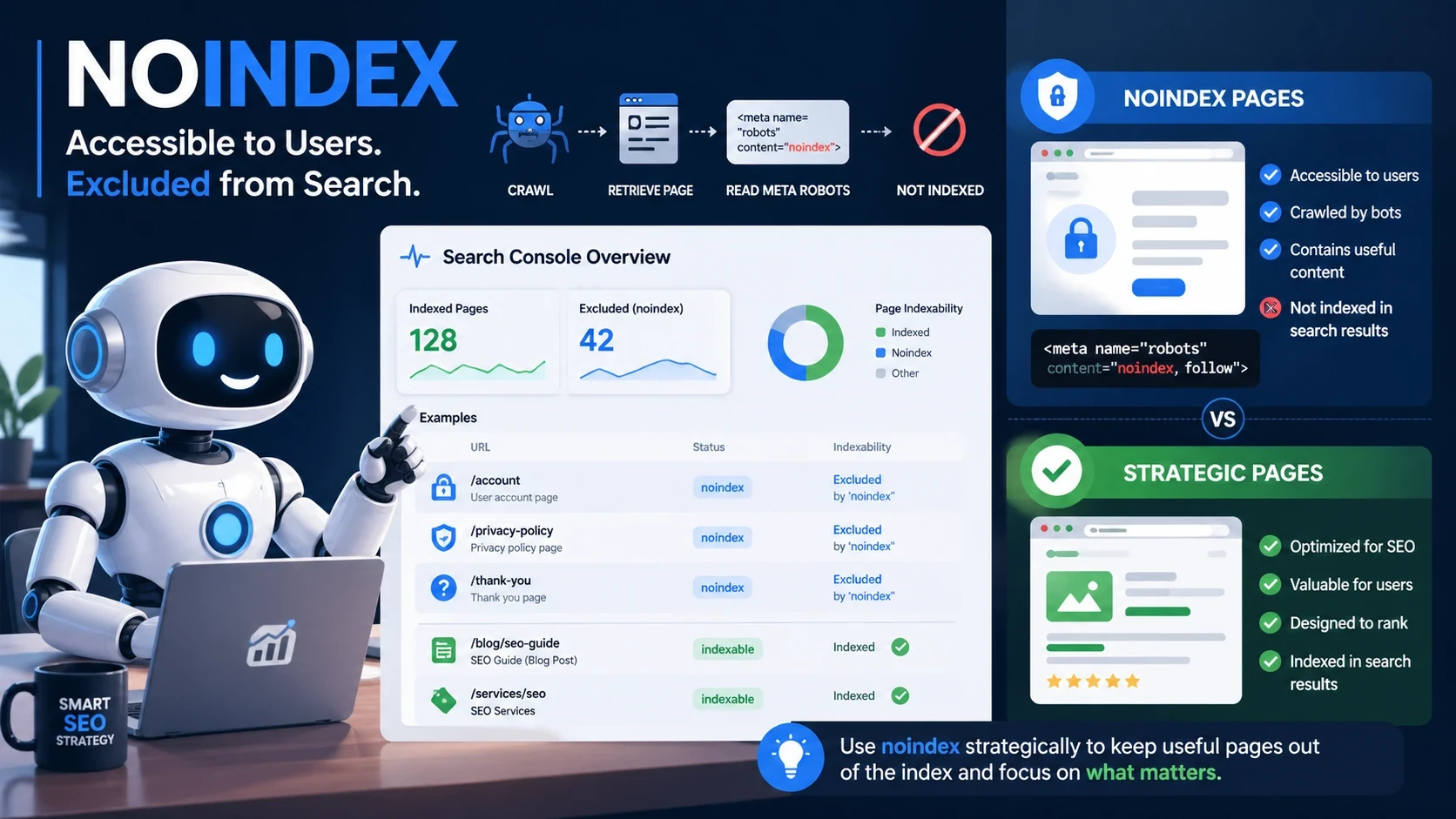
La directive noindex permet de demander aux moteurs de recherche de ne pas indexer une page. Elle est utile lorsqu’une page doit rester accessible aux utilisateurs, mais ne doit pas apparaître dans les résultats de recherche.
C’est un outil important en SEO technique. Il permet de mieux contrôler les pages réellement utiles à l’indexation : pages services, articles, catégories stratégiques, pages locales ou contenus à fort potentiel.
Mais noindex doit être utilisé avec méthode. Une mauvaise configuration peut faire disparaître des pages importantes de Google. À l’inverse, une absence de noindex peut laisser des pages faibles ou inutiles dans l’index.
Noindex SEO : définition simple
Noindex est une directive qui demande aux moteurs de recherche de ne pas indexer une page ou une ressource.
Exemple simple :
<meta name="robots" content="noindex">Cette directive indique aux robots compatibles que la page peut être consultée, mais qu’elle ne doit pas apparaître dans les résultats de recherche.
Il faut bien distinguer deux choses :
- la page peut rester accessible aux utilisateurs ;
- la page ne doit pas être conservée dans l’index du moteur.
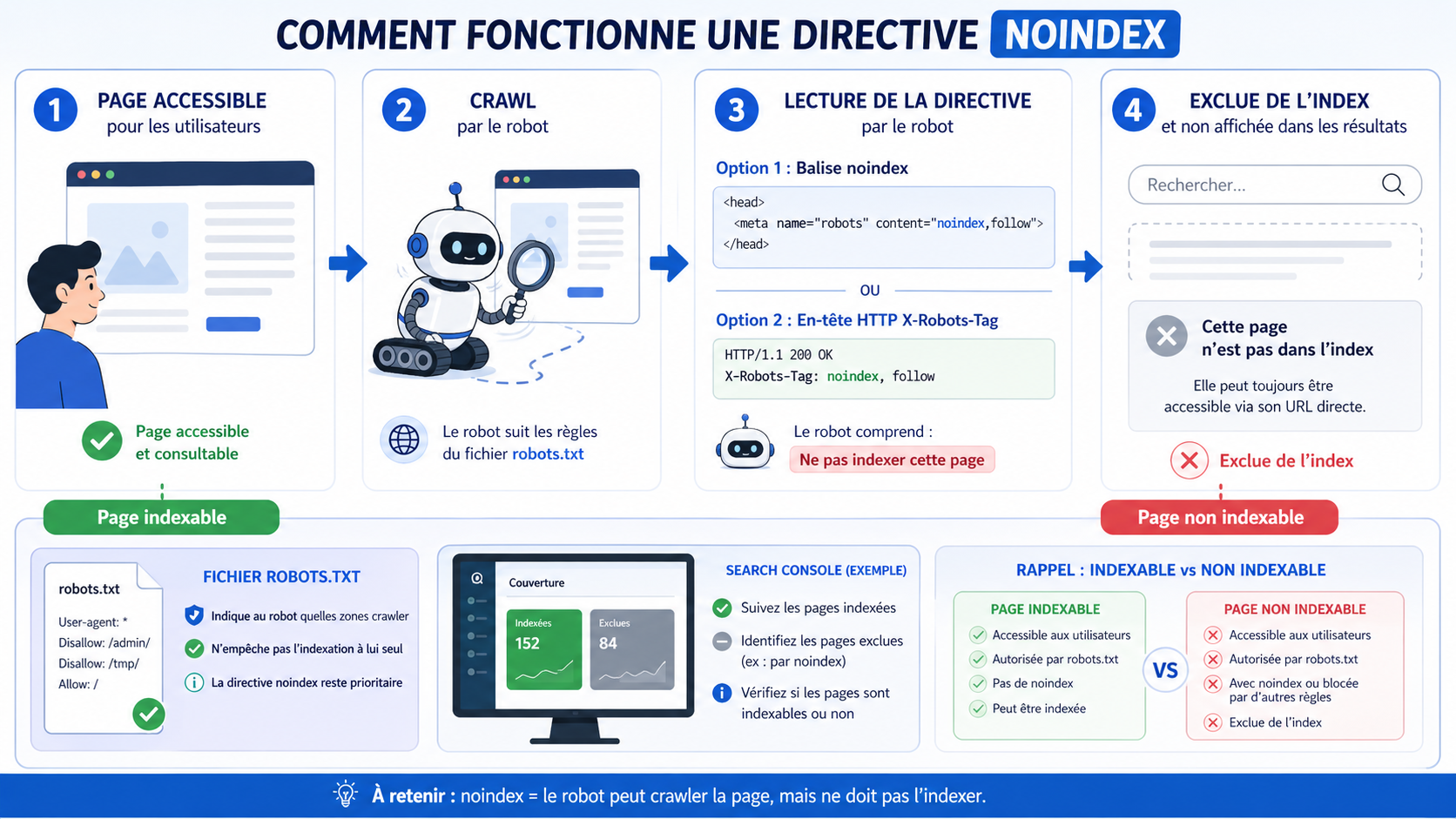
Noindex agit donc sur l’indexation, pas directement sur l’exploration. Pour que Google détecte la directive noindex, il doit pouvoir accéder à la page et lire la balise.
Référence utile : Google Search Central : bloquer l’indexation avec noindex .
Exemple de balise meta noindex
Pour une page HTML, la méthode la plus courante consiste à placer la balise noindex dans le <head> de la page.
<head> <meta name="robots" content="noindex"> </head>Cette directive s’adresse aux moteurs de recherche compatibles.
Il est aussi possible de cibler spécifiquement Googlebot :
<meta name="googlebot" content="noindex">Dans la majorité des cas, on utilise plutôt :
<meta name="robots" content="noindex">C’est plus simple et plus cohérent si l’on souhaite transmettre la directive aux différents moteurs.
X-Robots-Tag noindex : pour les PDF, images et fichiers non HTML
La balise meta noindex fonctionne pour les pages HTML. Pour les fichiers non HTML, comme les PDF, images, vidéos ou documents téléchargeables, il faut utiliser un en-tête HTTP.
Cet en-tête s’appelle X-Robots-Tag.
HTTP/1.1 200 OK X-Robots-Tag: noindexCette méthode est utile lorsque vous souhaitez empêcher l’indexation :
- d’un PDF ;
- d’une image ;
- d’un fichier média ;
- d’un document interne accessible ;
- d’une ressource générée automatiquement ;
- d’un fichier qui ne peut pas recevoir de balise HTML.
Exemple : un PDF de documentation peut être utile pour vos clients, mais ne pas avoir vocation à apparaître directement dans Google. Dans ce cas, le X-Robots-Tag: noindex peut être plus adapté qu’une balise HTML impossible à placer dans le fichier.
Référence utile : Google Search Central : robots meta tag et X-Robots-Tag .
Noindex, nofollow, index, follow : quelles différences ?
Les directives robots peuvent être combinées. Il faut donc bien comprendre leur rôle.
| Directive | Effet principal | Exemple |
|---|---|---|
index | Autoriser l’indexation. | Souvent implicite. |
noindex | Demander la non-indexation. | <meta name="robots" content="noindex"> |
follow | Autoriser le suivi des liens. | Souvent implicite. |
nofollow | Demander de ne pas suivre les liens. | <meta name="robots" content="nofollow"> |
noindex, follow | Ne pas indexer la page, mais laisser les liens suivables. | Cas fréquent en SEO. |
noindex, nofollow | Ne pas indexer la page et demander de ne pas suivre ses liens. | Cas plus restrictif. |
Dans beaucoup de cas SEO, noindex, follow est plus logique que noindex, nofollow. La page ne doit pas apparaître dans Google, mais elle peut encore contenir des liens utiles vers d’autres pages du site.
Exemple :
<meta name="robots" content="noindex, follow">Il faut toutefois rester prudent. Une page durablement en noindex ne doit pas devenir un pilier du maillage interne. Si une page est vraiment importante pour la stratégie SEO, elle doit généralement être indexable.
À lire aussi : Nofollow / Dofollow SEO : comprendre les attributs de liens .
Noindex vs robots.txt : quelle différence ?
C’est l’une des confusions les plus fréquentes en SEO technique. Noindex et robots.txt ne font pas la même chose.
| Méthode | Rôle | Effet |
|---|---|---|
| Noindex | Demander à ne pas indexer. | La page doit être crawlée pour que Google lise la directive. |
| Robots.txt | Bloquer ou limiter l’exploration. | Google peut ne pas voir la directive noindex. |
| Noindex + robots.txt bloqué | Mauvaise combinaison fréquente. | Le noindex peut ne pas être détecté. |
| Robots.txt seul | Contrôle du crawl. | Ne garantit pas la désindexation. |
Pour qu’un noindex soit pris en compte, Google doit pouvoir accéder à la page et lire la directive.
Si la page est bloquée dans le fichier robots.txt, Googlebot peut ne pas voir la balise noindex. La page peut alors continuer à apparaître dans les résultats si elle est connue par ailleurs, par exemple grâce à des liens externes.
Message à retenir :
Si vous voulez désindexer une page avec noindex, ne la bloquez pas dans robots.txt tant que Google n’a pas lu la directive.Référence utile : MDN : balise meta robots .
Noindex vs Canonical URL : quelle différence ?
Noindex et canonical sont parfois utilisés à tort pour résoudre les mêmes problèmes. Pourtant, ils ne répondent pas au même besoin.
| Méthode | Rôle | Quand l’utiliser |
|---|---|---|
| Noindex | Demander à ne pas indexer une page. | Page utile mais non souhaitée dans Google. |
| Canonical | Indiquer la version principale d’un contenu similaire. | Plusieurs URLs proches doivent rester accessibles. |
| Redirection 301 | Déplacer définitivement une URL. | Ancienne page remplacée. |
| 404 / 410 | Signaler une page supprimée. | Aucun équivalent pertinent. |
Noindex retire une page de l’index. Canonical indique une page principale. Ce n’est pas le même signal.
Exemple :
- une page de panier doit rester accessible mais ne doit pas être indexée : noindex ;
- une page produit existe avec plusieurs URLs similaires : canonical ;
- une ancienne page est remplacée par une nouvelle : redirection 301 ;
- une page supprimée n’a aucun équivalent : 404 ou 410.
À lire aussi : Canonical URL SEO : comprendre l’URL canonique et Redirect 301 SEO : comprendre la redirection permanente .
Quand utiliser noindex ?
Noindex est utile lorsqu’une page doit exister pour l’utilisateur, mais ne doit pas apparaître dans les résultats de recherche.
On peut l’utiliser sur :
- les pages de recherche interne ;
- les pages de filtres sans intérêt SEO ;
- les pages de tri ;
- les pages de test accessibles ;
- les pages de panier ;
- les pages compte client ;
- les pages de connexion ;
- les pages de remerciement ;
- les pages de confirmation ;
- certaines archives ;
- certains tags WordPress ;
- certains PDF sans intérêt SEO ;
- les pages pauvres que l’on doit conserver pour les utilisateurs.
| Type de page | Noindex pertinent ? |
|---|---|
| Panier e-commerce | Oui. |
| Compte client | Oui. |
| Page paiement | Oui. |
| Page service stratégique | Non. |
| Article de blog travaillé | Non. |
| Page catégorie SEO | Non. |
| Page filtre sans demande | Souvent oui. |
| PDF juridique important mais non SEO | À étudier. |
| Page de test accessible | Oui. |
La bonne question à se poser est simple : cette page a-t-elle une raison d’apparaître dans Google ?
Quand ne pas utiliser noindex ?
Noindex est puissant. Il faut donc éviter de l’appliquer sur des pages qui ont un rôle SEO important.
Il ne faut pas utiliser noindex sur :
- une page service stratégique ;
- une page catégorie e-commerce importante ;
- un article SEO travaillé ;
- une page locale ;
- une page pilier ;
- une page qui reçoit du trafic SEO utile ;
- une page ciblée dans le Keyword Mapping ;
- une page avec backlinks importants ;
- une page que vous voulez voir apparaître dans Google.
Une directive noindex accidentelle sur une page importante peut entraîner une perte de visibilité. La page peut sortir des résultats, même si son contenu est bon.
Message à retenir :
Une page stratégique doit être indexable, crawlable et cohérente avec le sitemap et le maillage interne.À lire aussi : Keyword Mapping SEO : associer les bons mots-clés aux bonnes pages .
Noindex et pages e-commerce
En e-commerce, noindex est très utile, mais il doit être appliqué avec discernement.
Certaines pages n’ont généralement pas vocation à être indexées :
- panier ;
- commande ;
- paiement ;
- compte client ;
- recherche interne ;
- tri par prix ;
- pages de session ;
- pages de comparaison faibles ;
- certains tags produits ;
- pages de résultats internes.
En revanche, certaines pages ne doivent pas être mises en noindex sans analyse :
- catégories principales ;
- sous-catégories avec volume de recherche ;
- pages marques ;
- pages modèles ;
- fiches produits importantes ;
- guides d’achat ;
- facettes répondant à une vraie demande SEO.
Exemple : une facette “chaussures running femme imperméables” peut représenter une vraie intention de recherche. Si la demande existe, il peut être plus intéressant de créer une page indexable dédiée plutôt que de mettre automatiquement la facette en noindex.
À lire aussi : SEO e-commerce : comment structurer les pages catégories pour mieux ranker .
Noindex et CMS : WordPress, Joomla, Prestashop, WooCommerce
Les CMS peuvent ajouter du noindex de plusieurs manières. Le risque, c’est qu’un réglage global ou un plugin modifie l’indexabilité de nombreuses pages sans que l’on s’en rende compte.
Le noindex peut venir :
- d’un plugin SEO ;
- d’un template ;
- d’un réglage global ;
- d’un module e-commerce ;
- d’un composant de recherche ;
- d’un réglage de catégories ou tags ;
- d’une extension de sécurité ;
- d’un mode maintenance ;
- d’un environnement de préproduction.
| CMS | Risque fréquent |
|---|---|
| WordPress | Tags, archives, catégories, réglages Yoast ou Rank Math. |
| Joomla | Articles, catégories, menus, vues générées par composants. |
| Prestashop | Filtres, recherche, pages compte, modules SEO. |
| WooCommerce | Produits, tags produits, filtres, panier, compte. |
| Shopify | Collections, tags, variantes, pages système. |
| Drupal | Taxonomies, vues, alias, contenus générés. |
Sur un site professionnel, il faut vérifier les règles noindex après chaque changement de plugin SEO, de template, de module e-commerce ou de configuration serveur.
Noindex et refonte SEO
Lors d’une refonte, noindex fait partie des points de contrôle critiques.
Le cas classique est simple : le site de préproduction est volontairement mis en noindex, puis cette directive reste en place après la mise en production.
Résultat : le nouveau site est en ligne, mais ses pages stratégiques demandent à Google de ne pas les indexer.
Les cas fréquents :
- le site de préproduction est en noindex ;
- le noindex reste par erreur après mise en ligne ;
- des templates ajoutent du noindex ;
- des pages stratégiques deviennent non indexables ;
- des pages de filtres changent de comportement ;
- les règles X-Robots-Tag changent côté serveur ;
- les pages anciennes redirigées ou supprimées ne sont pas traitées correctement.
Checklist refonte :
- Vérifier que la préproduction est bien protégée.
- Retirer le noindex sur la production au lancement.
- Crawler le site après mise en ligne.
- Contrôler les pages stratégiques.
- Vérifier les templates.
- Vérifier les en-têtes
X-Robots-Tag. - Contrôler Google Search Console.
- Vérifier les pages exclues par noindex.
À lire aussi : Refonte SEO : redirections, sitemaps et points de vigilance .
Noindex et environnement de préproduction
Un site de préproduction ne doit généralement pas être indexé. Mais noindex n’est pas toujours la protection la plus forte.
Plusieurs méthodes existent :
- authentification HTTP ;
- restriction IP ;
- noindex ;
- robots.txt selon contexte ;
- environnement non public.
La meilleure protection reste de rendre la préproduction inaccessible publiquement, par exemple avec un mot de passe ou une restriction IP.
Pourquoi ? Parce qu’un noindex demande que les robots puissent accéder à la page pour lire la directive. Pour une préproduction confidentielle, il vaut mieux empêcher l’accès.
Le noindex peut être une sécurité complémentaire, mais il ne doit pas être la seule barrière pour un environnement qui ne doit pas être visible.
Noindex et Search Console
Google Search Console permet d’identifier les pages exclues à cause d’une directive noindex.
Dans un audit SEO, il faut vérifier :
- les pages exclues par balise noindex ;
- les pages importantes passées en noindex ;
- les pages que vous pensiez indexables ;
- les pages de filtres exclues volontairement ;
- les pages de préproduction accidentellement découvertes ;
- l’évolution après une mise en ligne ou une refonte.
L’outil d’inspection d’URL permet aussi de vérifier comment Google voit une page donnée. C’est utile pour savoir si la directive noindex est détectée.
À lire aussi : Utiliser la Search Console pour améliorer réellement son SEO .
Comment vérifier si une page est en noindex ?
Il existe plusieurs méthodes simples pour vérifier si une page contient une directive noindex.
- Ouvrir le code source de la page.
- Chercher
<meta name="robots">. - Vérifier la valeur de l’attribut
content. - Inspecter les en-têtes HTTP.
- Vérifier la présence de
X-Robots-Tag. - Utiliser Screaming Frog ou Sitebulb.
- Utiliser une extension navigateur SEO.
- Inspecter l’URL dans Google Search Console.
Exemple à chercher dans le code HTML :
<meta name="robots" content="noindex">Exemple à chercher dans les en-têtes HTTP :
X-Robots-Tag: noindexIl faut aussi vérifier que la page n’est pas bloquée par robots.txt, sinon Google peut ne pas lire la directive.
Outils pour auditer le noindex
Un audit noindex doit croiser plusieurs signaux. Une page peut être accessible, bloquée, canonicalisée, présente dans le sitemap ou exclue par directive.
Outils utiles :
- Google Search Console ;
- Screaming Frog ;
- Sitebulb ;
- Semrush Site Audit ;
- Ahrefs Site Audit ;
- extension navigateur SEO ;
- inspection du code source ;
- vérificateur d’en-têtes HTTP ;
- logs serveur.
Les éléments à croiser :
- statut HTTP ;
- balise meta robots ;
- X-Robots-Tag ;
- robots.txt ;
- canonical ;
- sitemap XML ;
- liens internes ;
- profondeur de clic ;
- trafic organique ;
- backlinks ;
- intention SEO.
L’objectif n’est pas seulement de savoir si une page est en noindex. Il faut surtout savoir si ce noindex est volontaire, cohérent et utile.
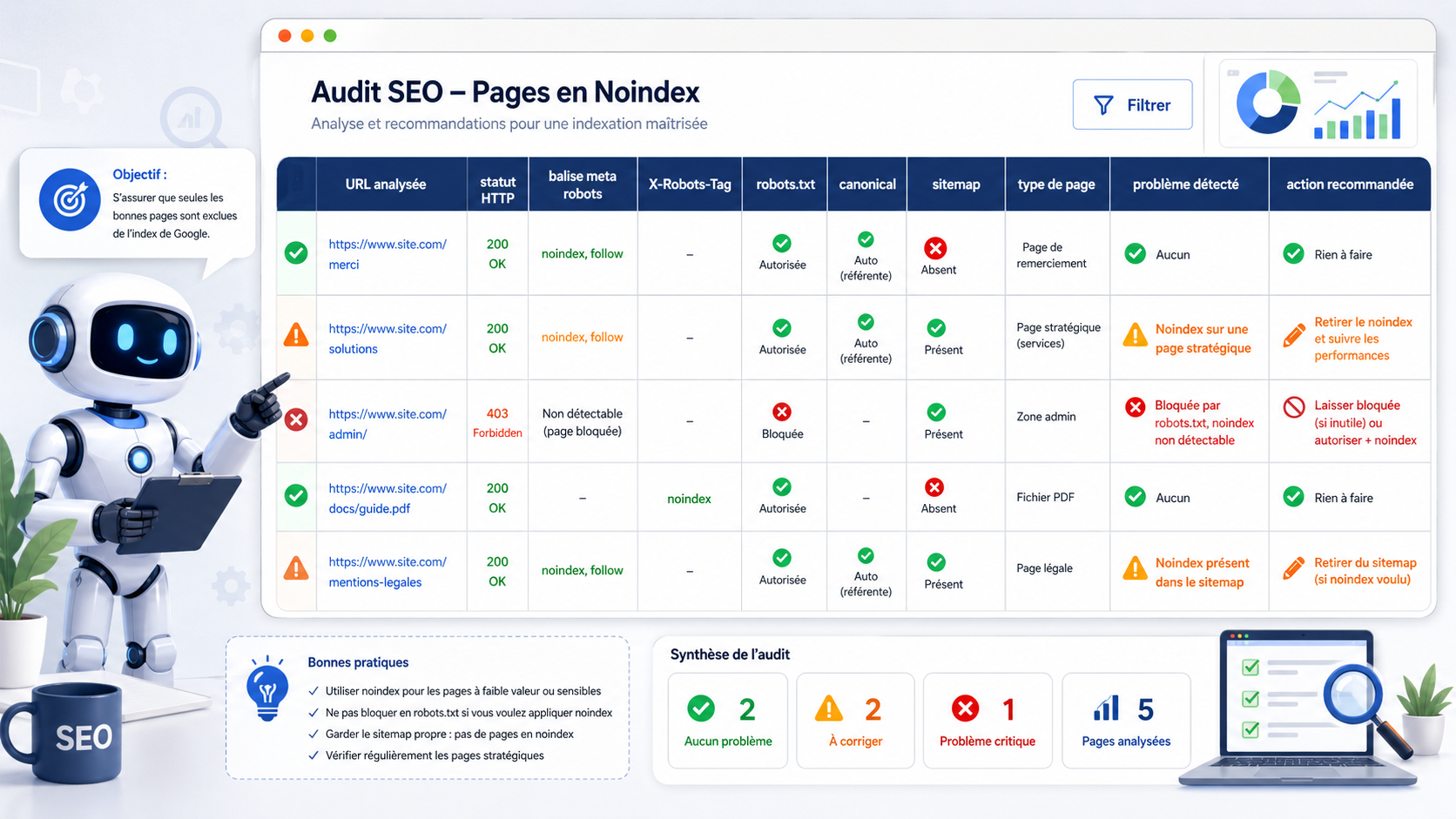
Les erreurs fréquentes avec noindex
Noindex est une directive simple, mais les erreurs peuvent avoir un impact fort sur la visibilité.
| Erreur | Pourquoi c’est un problème | Correction recommandée |
|---|---|---|
| Mettre noindex sur une page stratégique | Elle disparaît des résultats. | Retirer noindex. |
| Bloquer par robots.txt une page en noindex | Google peut ne pas lire le noindex. | Autoriser le crawl temporairement. |
| Confondre noindex et canonical | Le signal SEO n’est pas adapté. | Choisir selon le besoin réel. |
| Utiliser noindex à la place d’une 301 | L’ancienne URL reste accessible. | Rediriger si la page est remplacée. |
| Laisser noindex après mise en production | Perte de visibilité possible. | Vérifier au lancement. |
| Noindexer toutes les facettes e-commerce | Perte d’opportunités SEO. | Analyser les facettes utiles. |
| Mettre noindex sur une page avec backlinks | Perte de potentiel. | Rediriger ou optimiser selon le cas. |
| Oublier X-Robots-Tag sur PDF | Fichiers indexés inutilement. | Ajouter l’en-tête HTTP. |
| Ajouter noindex dans un template global | Risque massif sur tout le site. | Crawler tout le site. |
| Noindex + sitemap XML | Signal contradictoire. | Retirer du sitemap ou rendre indexable. |
Erreur fréquente : bloquer une page en robots.txt alors qu’elle est en noindex. Pour qu’un noindex soit pris en compte, Google doit pouvoir accéder à la page et lire la directive.
Exemple concret : noindex sur un site e-commerce
Prenons un exemple simple de boutique en ligne.
| URL | Type de page | Action recommandée |
|---|---|---|
/panier | Panier | Noindex. |
/mon-compte | Compte client | Noindex. |
/recherche?q=chaussures | Recherche interne | Noindex. |
/chaussures?tri=prix | Tri | Noindex ou canonical selon stratégie. |
/chaussures-running-femme | Sous-catégorie SEO | Indexable. |
/chaussures-running-femme-impermeables | Facette avec demande SEO | Indexable si contenu dédié. |
/merci-commande | Confirmation | Noindex. |
/guide-choisir-chaussures-running | Guide SEO | Indexable. |
Cet exemple montre bien que noindex ne doit pas être appliqué par type de page sans réflexion. Il faut toujours croiser la page avec son intention, sa valeur business, son trafic potentiel et son rôle dans l’arborescence.
Noindex et Keyword Mapping
Le Keyword Mapping détermine quelles pages doivent cibler quelles requêtes. Noindex doit respecter cette stratégie.
Concrètement :
- une page mappée sur une requête stratégique ne doit pas être en noindex ;
- une page sans intention SEO peut être en noindex ;
- une facette e-commerce peut être indexable si elle correspond à une vraie demande ;
- une page noindex ne doit pas être présente dans le sitemap XML des pages indexables.
| Page | Rôle SEO | Indexabilité attendue |
|---|---|---|
| Page service audit SEO | Page commerciale stratégique | Indexable. |
| Article prix audit SEO | Intention tarifaire | Indexable. |
| Page panier | Fonctionnelle | Noindex. |
| Recherche interne | Fonctionnelle / faible SEO | Noindex. |
| Facette avec demande SEO | Opportunité longue traîne | Indexable si travaillée. |
Noindex doit donc être décidé en fonction du rôle réel de la page. Il ne doit pas contredire le Keyword Mapping.
Noindex et Link Juice
Une page noindex peut être crawlée et contenir des liens. Mais elle ne doit pas être considérée comme une page stratégique de redistribution SEO.
En pratique, il faut retenir plusieurs règles :
- les pages importantes doivent rester indexables ;
- les pages faibles en noindex ne doivent pas porter le maillage principal ;
- noindex ne doit pas servir à masquer un mauvais maillage interne ;
- les liens internes importants doivent partir de pages utiles et cohérentes ;
- une page avec backlinks importants doit être analysée avant d’être mise en noindex.
Si une page reçoit des backlinks mais ne doit plus être indexée, il faut se demander s’il ne vaut pas mieux l’optimiser, la fusionner ou la rediriger vers une page pertinente.
À lire aussi : Link Juice SEO : comprendre le jus de lien et la circulation de l’autorité .
Noindex SEO : ce qu’il faut retenir
Noindex demande aux moteurs de recherche de ne pas indexer une page ou une ressource.
Il peut être appliqué via une balise meta robots pour les pages HTML ou via un en-tête HTTP X-Robots-Tag pour les fichiers non HTML comme les PDF.
Noindex est utile pour les pages qui doivent rester accessibles mais ne pas apparaître dans Google : panier, compte client, recherche interne, pages de test, pages de remerciement ou certains filtres sans intérêt SEO.
Il ne remplace pas une redirection 301, une canonical ou une bonne architecture de site.
Point essentiel : si vous voulez que Google voie le noindex, la page ne doit pas être bloquée dans le fichier robots.txt avant que la directive soit lue.
Vous avez des pages inutiles dans l’index, des filtres e-commerce visibles dans Google ou une refonte en préparation ? Un audit SEO permet de vérifier les balises noindex, les règles robots.txt, les canonicals et les pages réellement importantes à conserver dans l’index.
À lire aussi : Pourquoi faire un audit SEO ? .
FAQ sur Noindex
Que veut dire noindex en SEO ?
Noindex est une directive qui demande aux moteurs de recherche de ne pas indexer une page ou une ressource.
À quoi sert la balise noindex ?
Elle sert à garder une page accessible aux utilisateurs tout en demandant aux moteurs de ne pas l’afficher dans les résultats de recherche.
Comment ajouter noindex à une page ?
Pour une page HTML, il faut ajouter une balise <meta name="robots" content="noindex"> dans le <head> de la page.
Quelle différence entre noindex et robots.txt ?
Noindex agit sur l’indexation. Robots.txt agit sur l’exploration. Si une page est bloquée par robots.txt, Google peut ne pas voir la directive noindex.
Quelle différence entre noindex et canonical ?
Noindex demande de ne pas indexer une page. Canonical indique la version principale d’un contenu lorsque plusieurs URLs similaires existent.
Quelle différence entre noindex et redirection 301 ?
Noindex garde la page accessible mais hors index. Une redirection 301 envoie automatiquement l’utilisateur et les moteurs vers une autre URL.
Peut-on noindexer un PDF ?
Oui, mais il faut utiliser un en-tête HTTP X-Robots-Tag: noindex, car un PDF ne peut pas recevoir de balise meta HTML classique.
Comment vérifier si une page est en noindex ?
Il faut inspecter le code source, chercher la balise meta robots, vérifier les en-têtes HTTP et contrôler l’URL dans Google Search Console.
Faut-il mettre noindex sur les pages de filtres e-commerce ?
Pas automatiquement. Certaines pages de filtres n’ont aucun intérêt SEO, mais d’autres peuvent répondre à une vraie demande et mériter une page indexable dédiée.
Pourquoi une page noindex apparaît-elle encore dans Google ?
Cela peut arriver si Google n’a pas encore recrawlé la page, si la page est bloquée par robots.txt, ou si la directive noindex n’est pas correctement détectée.



