
L’indexing, ou indexation en français, est une étape essentielle du référencement naturel. Une page peut être publiée, accessible depuis votre site et visible pour vos visiteurs, sans pour autant apparaître dans Google. Pour être affichée dans les résultats de recherche, elle doit d’abord être ajoutée à l’index de Google.
C’est une confusion fréquente. Beaucoup de propriétaires de sites pensent qu’une page mise en ligne devient automatiquement visible sur Google. En réalité, Google doit d’abord la découvrir, l’explorer, l’analyser, puis décider s’il l’ajoute ou non à son index.
Comprendre l’indexing permet de mieux diagnostiquer les problèmes de visibilité. Une page absente de Google n’est pas toujours “mal référencée”. Elle peut tout simplement ne pas être indexée.
Indexing SEO : définition simple
L’indexing désigne le processus par lequel Google analyse une page web puis décide de l’ajouter ou non à son index. En français, on parle d’indexation.
Une page indexée peut apparaître dans les résultats de recherche Google. Une page non indexée, elle, ne peut pas générer de trafic naturel depuis Google, même si elle est parfaitement accessible sur votre site.
Il faut faire attention à une nuance importante : une page indexée n’est pas forcément bien positionnée. L’indexation signifie seulement que Google a ajouté la page à sa base. Le classement dans les résultats vient ensuite.
Google regroupe les sujets liés à l’exploration et à l’indexation dans sa documentation Search Central. Ces ressources expliquent comment aider Google à rechercher, analyser et afficher les contenus d’un site dans les résultats de recherche.
Référence utile : Google Search Central : exploration et indexation .
Crawl, indexing, ranking : trois étapes différentes
Pour bien comprendre l’indexation, il faut la replacer dans la chaîne complète du référencement naturel. Une page ne passe pas directement de la publication à la première page de Google.
| Étape | Traduction | Ce que cela signifie |
|---|---|---|
| Crawl | Exploration | Googlebot visite la page et récupère les informations qu’il peut lire. |
| Indexing | Indexation | Google analyse la page et peut décider de l’ajouter à son index. |
| Ranking | Positionnement | Google classe la page dans ses résultats selon une requête précise. |
Cette distinction est fondamentale. Une page peut être crawlée sans être indexée. Elle peut aussi être indexée sans être bien positionnée. Et une page peut être bien positionnée sur une requête, mais invisible sur une autre.
Le crawl est donc la visite. L’indexing est l’entrée possible dans la base de Google. Le ranking est le classement final dans les résultats.
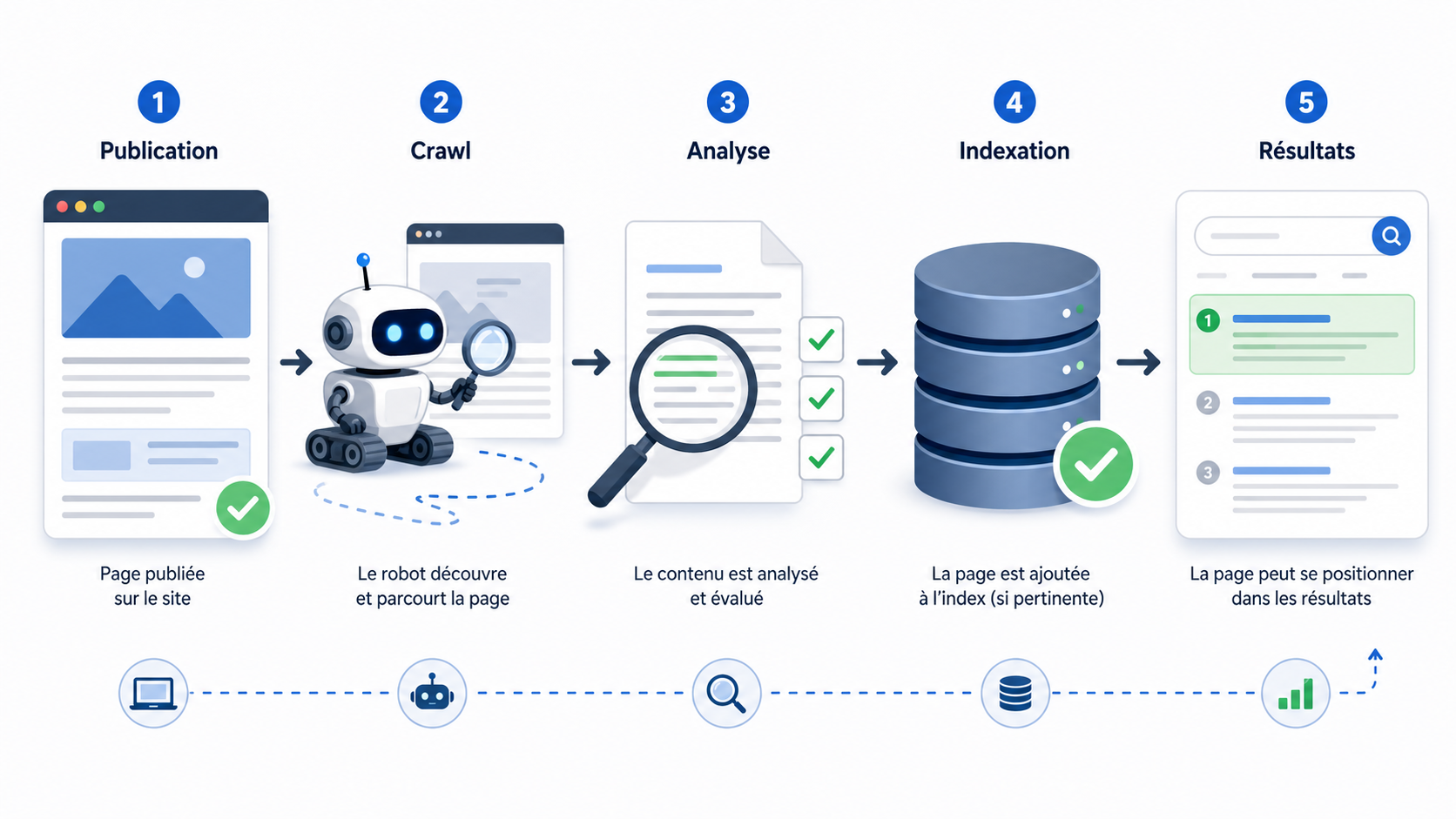
À lire aussi : Crawl en SEO : comprendre comment Google explore votre site .
À quoi sert l’index de Google ?
L’index de Google peut être comparé à une immense bibliothèque. Google ne parcourt pas tout le web en direct à chaque recherche. Il s’appuie sur les pages qu’il connaît déjà, qu’il a analysées et qu’il a intégrées dans son index.
Lorsqu’un internaute tape une requête, Google cherche dans son index les contenus qui semblent les plus pertinents. Il les classe ensuite selon de nombreux critères : pertinence du contenu, intention de recherche, qualité perçue, structure de la page, popularité, contexte, localisation et autres signaux.
Une page absente de l’index ne peut donc pas participer à cette sélection. Elle existe sur le web, mais elle n’est pas disponible dans la base de résultats de Google.
C’est pour cela que l’indexation est une étape clé. Elle ne garantit pas le trafic, mais elle rend le trafic possible.
Comment Google décide-t-il d’indexer une page ?
Google ne donne pas une recette unique qui garantirait l’indexation. Une page peut être techniquement accessible et pourtant ne pas être indexée. L’indexation dépend d’un ensemble de signaux.
Parmi les points à surveiller, on retrouve notamment :
- l’accessibilité technique de la page ;
- l’absence de balise
noindex; - l’absence de blocage inutile dans le fichier
robots.txt; - la qualité et l’utilité du contenu ;
- la différence réelle avec les autres pages du site ;
- la présence de liens internes vers la page ;
- la cohérence de la balise canonical ;
- la présence de l’URL dans un sitemap XML propre ;
- la capacité de Google à rendre la page si elle utilise JavaScript ;
- la stabilité technique du serveur.
Une page bien indexable doit donc être accessible, utile, distincte et correctement intégrée au reste du site.
Pourquoi une page peut ne pas être indexée ?
Une page non indexée n’est pas toujours le signe d’une pénalité ou d’un grave problème technique. Dans beaucoup de cas, Google estime simplement qu’il n’a pas encore assez de raisons de l’ajouter à son index.
La page est trop récente
Une nouvelle page n’est pas toujours indexée immédiatement. Google doit d’abord la découvrir, l’explorer, puis l’analyser. Le délai peut varier selon la taille du site, sa fréquence de mise à jour, son maillage interne et sa qualité globale.
Pour une page importante, il est utile de vérifier qu’elle est présente dans le sitemap XML et qu’elle reçoit au moins quelques liens internes depuis des pages déjà connues de Google.
La page est orpheline ou mal reliée
Une page orpheline est une page qui ne reçoit aucun lien interne depuis le reste du site. Elle peut exister, mais elle reste difficile à découvrir et à interpréter.
Le maillage interne aide Google à comprendre quelles pages sont importantes. Une page sans lien interne envoie souvent un signal faible : elle semble secondaire, isolée ou peu intégrée.
À lire aussi : Netlinking interne : les erreurs courantes qui ruinent vos efforts SEO .
Le contenu est trop faible ou trop proche d’une autre page
L’indexation n’est pas seulement un sujet technique. Beaucoup de pages restent non indexées parce qu’elles n’apportent pas assez de valeur.
Cela peut arriver avec des contenus trop courts, des pages générées automatiquement, des fiches produits très proches, des pages locales répétitives ou des articles qui reprennent les mêmes idées qu’une page déjà existante.
Dans ce cas, la bonne réponse n’est pas seulement de demander l’indexation dans Google Search Console. Il faut enrichir la page, clarifier son intention, ajouter des exemples, renforcer son utilité et mieux la relier au reste du site.
À lire aussi : Thin content : pourquoi vos pages ne cassent pas les classements et comment les réparer .
Une balise noindex bloque l’indexation
La balise noindex indique aux moteurs de recherche qu’une page ne doit pas être ajoutée à l’index. Elle peut être utile pour certaines pages, mais elle devient problématique si elle reste en place sur une page stratégique.
Google explique qu’une règle noindex peut empêcher une page d’apparaître dans les résultats de recherche. Cette directive peut être placée dans une balise meta ou dans un en-tête HTTP X-Robots-Tag.
Référence utile : Google Search Central : bloquer l’indexation avec noindex .
Le fichier robots.txt bloque l’exploration
Le fichier robots.txt sert à indiquer aux robots les URL qu’ils peuvent ou ne peuvent pas explorer. Il ne doit pas être confondu avec la balise noindex.
Google précise que le fichier robots.txt sert surtout à contrôler l’exploration et à éviter de surcharger un site. Il ne doit pas être utilisé comme méthode principale pour empêcher une page d’apparaître dans les résultats.
À lire aussi : Robots.txt expliqué simplement : syntaxe, bonnes pratiques et impact SEO .
Référence utile : Google Search Central : présentation du fichier robots.txt .
Une mauvaise URL canonique envoie Google ailleurs
La balise canonical sert à indiquer la version principale d’une page lorsque plusieurs URL présentent des contenus proches. Elle est très utile, mais elle peut créer des problèmes lorsqu’elle est mal configurée.
Si une page importante pointe en canonical vers une autre URL, Google peut choisir de ne pas indexer la page attendue. Il considère alors qu’une autre version est prioritaire.
Le site contient trop de pages inutiles
Sur certains sites, le problème ne vient pas d’une page isolée, mais d’un excès d’URL à faible valeur.
On retrouve souvent ce problème sur les sites e-commerce avec des filtres, des tris, des variantes, des pages de tags, des archives ou des résultats de recherche interne. Google peut alors explorer beaucoup de pages peu utiles et ignorer des pages plus importantes.
À lire aussi : SEO e-commerce : comment structurer les pages catégories pour mieux ranker .
| Problème | Symptôme possible | Correction recommandée |
|---|---|---|
Page en noindex | La page ne peut pas entrer dans l’index. | Retirer la directive si la page doit être visible. |
| Page orpheline | Google la découvre mal ou la juge peu importante. | Ajouter des liens internes depuis des pages fortes. |
| Contenu trop proche | Google privilégie une autre page similaire. | Différencier l’intention et enrichir le contenu. |
| Mauvaise canonical | Google sélectionne une autre URL comme version principale. | Corriger la balise canonical. |
| URL absente du sitemap | La découverte de la page est moins fluide. | Ajouter l’URL au sitemap XML si elle est stratégique. |
| Blocage robots.txt | Google ne peut pas explorer correctement la page. | Corriger la directive Disallow si nécessaire. |
Comment savoir si une page est indexée ?
Plusieurs méthodes permettent de vérifier l’indexation d’une page. Certaines sont rapides, d’autres plus fiables.
Utiliser Google Search Console
Google Search Console est l’outil le plus utile pour suivre l’état d’indexation d’une URL. L’outil d’inspection d’URL permet de consulter les informations dont Google dispose sur une page précise.
Il permet notamment de vérifier si une page est indexée, si elle peut être indexée, si Google a rencontré un blocage, quelle URL canonique a été sélectionnée, ou encore si une demande d’indexation peut être envoyée.
Référence utile : Aide Google Search Console : outil d’inspection d’URL .
Utiliser la recherche site:
La commande site: peut donner une première indication. Par exemple :
site:exemple.com/ma-pageSi la page apparaît, elle est probablement indexée. Si elle n’apparaît pas, cela mérite une vérification dans Google Search Console. Cette commande reste un indicateur rapide, mais elle ne remplace pas l’outil d’inspection d’URL.
Analyser les logs serveur
Pour les sites plus importants, les fichiers journaux permettent de vérifier si Googlebot passe réellement sur les URL. C’est une information précieuse, car elle montre les visites effectives des robots sur le serveur.
À lire aussi : Analyse de fichiers journaux : l’outil SEO sous-estimé qui dit la vérité sur votre site .
Consulter le rapport d’indexation des pages
Le rapport d’indexation des pages dans Search Console permet d’identifier les grandes familles de problèmes : pages exclues, pages découvertes mais non indexées, pages explorées mais non indexées, erreurs serveur, redirections ou blocages.
Ce rapport doit être lu avec méthode. L’objectif n’est pas de faire indexer toutes les URL, mais de comprendre si les pages importantes sont bien prises en compte.
Comment favoriser l’indexation d’une page ?
On ne peut pas forcer Google à indexer une page. On peut en revanche lui donner de bonnes raisons de le faire.
- Ajouter la page au sitemap XML si elle est stratégique.
- Créer des liens internes depuis des pages importantes.
- Vérifier que la page n’est pas en
noindex. - Vérifier qu’elle n’est pas bloquée par le fichier
robots.txt. - Améliorer le contenu si la page est trop courte ou trop proche d’une autre.
- Corriger la balise canonical si elle pointe vers une mauvaise URL.
- Améliorer le temps de chargement et la stabilité technique.
- Éviter les erreurs serveur.
- Demander une indexation via Google Search Console après correction.
Google permet de demander l’exploration d’une URL individuelle via l’outil d’inspection d’URL. Cette action peut aider à signaler une page, mais elle ne garantit pas son indexation.
Référence utile : Google Search Central : demander à Google d’explorer de nouveau vos URL .
À lire aussi : Les meilleurs outils pour créer un plan de site XML .
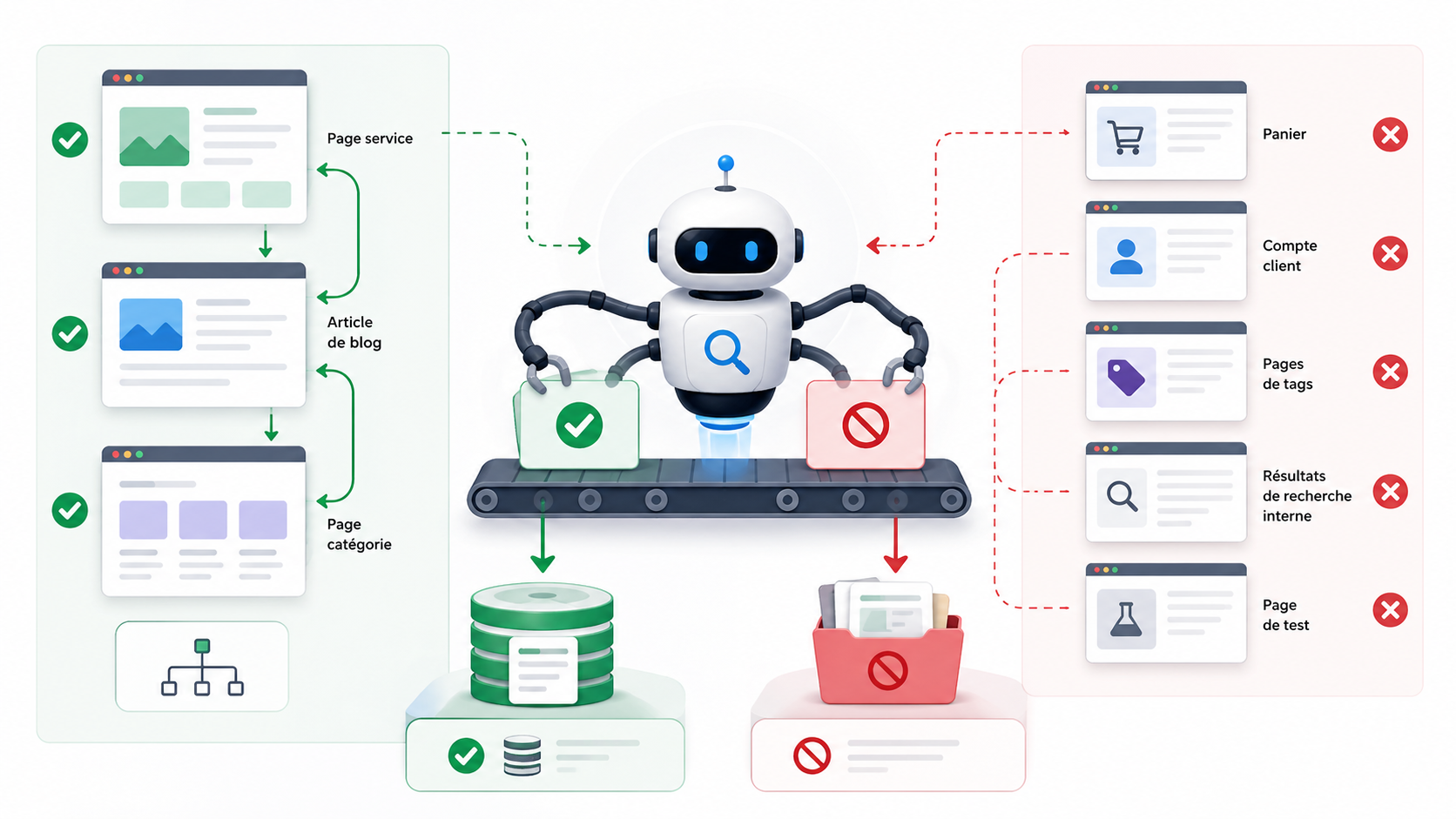
Faut-il chercher à indexer toutes les pages ?
Non. Une bonne stratégie SEO ne consiste pas à tout indexer. Elle consiste à faire indexer les bonnes pages.
Certaines pages n’ont pas vocation à apparaître dans Google. Elles peuvent être utiles pour le fonctionnement du site, mais inutiles pour le référencement naturel.
On peut généralement éviter l’indexation de pages comme :
- les pages de remerciement après formulaire ;
- les pages de panier ;
- les pages de compte client ;
- les résultats de recherche interne ;
- les filtres sans intérêt SEO ;
- les tags inutiles ;
- les pages de test ;
- les environnements de préproduction ;
- les pages très proches d’autres contenus déjà publiés.
Le but est de concentrer l’attention de Google sur les contenus qui ont une vraie valeur : pages services, pages catégories, articles utiles, contenus experts, guides, pages locales, pages marques ou pages produits importantes.
C’est un point important sur les sites e-commerce, les blogs anciens et les sites ayant connu plusieurs refontes.
Exemple concret : une page publiée mais non indexée
Prenons un cas simple. Une PME publie une page intitulée “Audit SEO Toulouse”. La page est en ligne, le texte existe, l’URL fonctionne, mais elle reste absente de Google après plusieurs semaines.
En vérifiant la situation, on découvre plusieurs problèmes :
- la page ressemble beaucoup à une autre page “Référencement naturel Toulouse” ;
- elle n’a presque aucun lien interne ;
- elle n’est pas présente dans le sitemap XML ;
- sa balise title est trop générique ;
- la page ne présente pas assez d’exemples, de preuves ou de cas concrets.
Dans ce cas, la page peut être crawlée, mais Google peut décider de ne pas l’indexer. Il peut estimer qu’elle n’apporte pas assez de différence ou de valeur par rapport à ce qu’il connaît déjà.
Les corrections possibles sont assez claires :
- clarifier l’intention de la page ;
- différencier le contenu de la page SEO généraliste ;
- ajouter des exemples de problèmes détectés en audit ;
- renforcer les liens internes depuis les articles proches ;
- ajouter la page au sitemap XML ;
- vérifier la balise canonical ;
- demander une nouvelle exploration dans Search Console après correction.
L’indexation n’est donc pas une simple formalité. Elle dépend de la valeur perçue de la page, de sa place dans le site et de sa cohérence avec l’ensemble éditorial.
Quand faut-il auditer l’indexation d’un site ?
Un audit d’indexation devient utile lorsque le site contient beaucoup de pages, publie régulièrement ou rencontre des problèmes de visibilité sans explication évidente.
Je recommande de vérifier l’indexation dans plusieurs situations :
- après une refonte ;
- après une migration de CMS ;
- lorsqu’une baisse de trafic apparaît dans Search Console ;
- lorsque beaucoup de pages restent en “explorée, actuellement non indexée” ;
- lorsqu’un site e-commerce génère trop d’URL inutiles ;
- lorsqu’un blog ancien contient beaucoup d’articles proches ;
- lorsque des pages stratégiques ne sortent pas sur Google.
Un audit SEO permet de vérifier si les pages importantes sont bien crawlées, indexables, différenciées, maillées et cohérentes avec les objectifs de visibilité.
À lire aussi : Référencement : que faire lorsqu’une page est explorée mais non indexée par Google ? et Pourquoi faire un audit SEO ? .
À retenir
L’indexing est l’étape où Google décide si une page peut entrer dans son index. Une page publiée n’est donc pas automatiquement visible dans les résultats de recherche.
Pour être indexée, une page doit être accessible, lisible, utile, différenciée et correctement intégrée au site. Le sitemap XML, le maillage interne, la balise canonical, les directives robots, la qualité du contenu et la structure du site jouent tous un rôle.
Une page indexée n’est pas forcément bien positionnée. L’indexation ouvre la porte à la visibilité, mais le classement dépend ensuite de la pertinence, de l’intention de recherche, de la concurrence et des signaux de qualité.
Si vos pages sont publiées mais restent invisibles sur Google, il faut d’abord vérifier leur statut d’indexation avant de conclure à un problème de positionnement.
FAQ sur l’indexing SEO
Que veut dire indexing en SEO ?
L’indexing désigne l’indexation d’une page par Google. C’est le processus par lequel Google analyse une page puis décide de l’ajouter ou non à son index.
Quelle est la différence entre crawl et indexing ?
Le crawl correspond à l’exploration d’une page par Googlebot. L’indexing correspond à l’ajout éventuel de cette page dans l’index de Google. Une page peut être crawlée sans être indexée.
Une page indexée est-elle forcément bien positionnée ?
Non. Une page indexée est simplement présente dans l’index de Google. Son positionnement dépend ensuite de la qualité du contenu, de l’intention de recherche, de la concurrence, du maillage interne, de l’autorité et d’autres signaux SEO.
Comment savoir si une page est indexée par Google ?
La méthode la plus fiable consiste à utiliser l’outil d’inspection d’URL dans Google Search Console. La commande site: peut donner une indication rapide, mais elle ne remplace pas Search Console.
Pourquoi Google n’indexe pas une page ?
Google peut ne pas indexer une page si elle est trop récente, trop faible, trop proche d’une autre, mal maillée, bloquée par noindex, difficile à explorer ou mal configurée avec une balise canonical.
Peut-on forcer Google à indexer une page ?
Non. On peut demander une exploration via Google Search Console, mais Google reste libre d’indexer ou non la page. Il faut surtout améliorer la qualité, l’accessibilité et l’intégration de la page dans le site.
Combien de temps faut-il pour qu’une page soit indexée ?
Il n’existe pas de délai garanti. Une page bien maillée, utile, présente dans le sitemap et publiée sur un site actif peut être indexée plus rapidement qu’une page isolée ou peu différenciée.
Faut-il indexer toutes les pages d’un site ?
Non. Il vaut mieux faire indexer les pages utiles pour le SEO : pages services, pages catégories, articles de fond, guides, pages locales ou contenus stratégiques. Les pages techniques ou sans intérêt SEO peuvent rester hors index.
Quelle différence entre noindex et robots.txt ?
Noindex demande aux moteurs de ne pas indexer une page. Robots.txt sert à contrôler l’exploration. Pour empêcher une page d’apparaître dans Google, noindex est généralement plus adapté que robots.txt.
Le sitemap garantit-il l’indexation ?
Non. Le sitemap aide Google à découvrir les URL importantes, mais il ne garantit pas leur indexation. La qualité de la page, son maillage interne et sa cohérence restent essentiels.
Références utiles
Prompts pour générer les images de l’article
Deux images suffisent pour illustrer cet article. La première doit expliquer la chaîne entre publication, crawl, indexation et positionnement. La seconde doit montrer pourquoi certaines pages ne méritent pas toujours d’entrer dans l’index.
Image 1 — De la publication à l’indexation Google
Emplacement conseillé : après la partie “Crawl, indexing, ranking : trois étapes différentes”.
Alt recommandé : Schéma montrant les étapes entre la publication d’une page, son crawl, son indexation et son positionnement sur Google.
Illustration pédagogique en format paysage 16:9 montrant le parcours d’une page web depuis sa publication jusqu’à son indexation dans Google. Représenter clairement les étapes : publication de la page, crawl par un robot d’exploration, analyse du contenu, ajout éventuel à l’index, puis positionnement dans les résultats de recherche. Style professionnel, clair, moderne, adapté à un article de blog SEO, couleurs sobres, interface web stylisée, sans logo Google officiel, sans texte illisible, rendu propre et didactique.Image 2 — Pages indexables et pages à ne pas indexer
Emplacement conseillé : dans la partie “Faut-il chercher à indexer toutes les pages ?”.
Alt recommandé : Illustration montrant la différence entre les pages utiles à indexer et les pages techniques à exclure de l’index Google.
Illustration professionnelle en format paysage 16:9 représentant un site web avec deux groupes de pages : d’un côté des pages stratégiques bien structurées prêtes à être indexées, comme pages services, articles et pages catégories ; de l’autre des pages techniques ou inutiles à garder hors index, comme panier, compte client, tags, résultats de recherche interne et pages de test. Ajouter un robot d’exploration qui trie les pages avant l’indexation. Style moderne, clair, pédagogique, adapté à un blog SEO, symboles de sitemap, index, noindex et liens internes, sans marque officielle, sans texte trop présent.


