
Explication des balises Meta Robots et X-Robots
Georges Corre Référencement
Les balises Meta Robots et X-Robots font partie de ces réglages discrets qu’on ne regarde pas… jusqu’au jour où le trafic disparaît.
Une ligne mal placée, un noindex oublié, un PDF mal contrôlé, et Google applique la règle sans discuter.
Pas de pénalité. Pas d’alerte. Juste un site qui sort des résultats.
Ces balises ne sont pas compliquées.
Mais elles demandent de la méthode, du recul… et un peu d’expérience terrain.
Qu'est-ce qu'une balise méta-robots ?
Une balise méta-robots est un morceau de code HTML qui indique aux robots des moteurs de recherche comment explorer, indexer et afficher le contenu d'une page.
Elle se trouve dans la section <head> de la page et peut ressembler à ceci :
<meta name="robots" content="noindex">
La balise méta-robots de l'exemple ci-dessus indique à tous les robots d'exploration des moteurs de recherche de ne pas indexer la page.
Voyons à quoi peuvent servir les balises méta-robots, pourquoi elles sont importantes pour le référencement et comment les utiliser correctement.
Ressources complémentaires pour maîtriser l’indexation et le crawl
- Robots.txt expliqué simplement – Comprendre la complémentarité entre robots.txt et balises meta robots.
- Crawl budget : les fondamentaux – Comment le contrôle des robots influence l’exploration de votre site.
- Balises hreflang : erreurs fréquentes – Les pièges d’indexation à éviter sur les sites multilingues.
- Refonte SEO : redirections et sitemaps – Bien gérer l’indexation lors d’une refonte ou d’une migration.
- Comment savoir si votre site a été pénalisé par Google – Identifier les conséquences d’une mauvaise gestion des directives robots.
Meta Robots vs. Robots.txt
Les balises méta-robots et les fichiers robots.txt ont des fonctions similaires mais servent à des fins différentes.
Un fichier robots.txt est un fichier texte unique qui s'applique à l'ensemble du site. Et indique aux moteurs de recherche les pages à explorer.
Une balise méta-robots s'applique uniquement à la page contenant la balise. Et indique aux moteurs de recherche comment explorer, indexer et afficher les informations de cette page uniquement.
Meta Robots vs X-Robots : quand utiliser quoi ?
Cas d’usage | Meta Robots | X-Robots-Tag |
Page HTML classique | ✅ Oui | ⚠️ Possible mais inutile |
PDF / document non HTML | ❌ Non | ✅ Oui |
Images, vidéos, fichiers | ❌ Non | ✅ Oui |
Contrôle page par page | ✅ Oui | ⚠️ Plus lourd |
Règles globales serveur | ❌ Non | ✅ Oui |
Facilité d’implémentation | ⭐⭐⭐⭐ | ⭐⭐ |
En clair :
- Meta Robots → contrôle fin, simple, au niveau page HTML
- X-Robots-Tag → contrôle serveur, indispensable pour les ressources non HTML
👉 Si la page a un <head>, Meta Robots suffit dans 90 % des cas.

À quoi servent les balises méta robots ?
Les balises méta robots permettent de contrôler la manière dont Google explore et indexe le contenu d'une page. Cela inclut les choix suivants :
- Inclure une page dans les résultats de recherche
- Suivre les liens sur une page
- Indexer les images sur une page
- Afficher les résultats mis en cache de la page sur les pages de résultats des moteurs de recherche (SERP)
- Afficher un extrait de la page sur les SERP
Ci-dessous, nous allons explorer les attributs que vous pouvez utiliser pour indiquer aux moteurs de recherche comment interagir avec vos pages.
Mais d'abord, discutons de l'importance des balises méta robots et de la manière dont elles peuvent affecter le référencement de votre site.
Comment les balises méta robots affectent-elles le référencement ?
Les balises méta robots aident Google et les autres moteurs de recherche à explorer et indexer efficacement vos pages.
En particulier pour les sites volumineux ou fréquemment mis à jour.
Après tout, vous n'avez probablement pas besoin que toutes les pages de votre site soient classées.
Par exemple, vous ne souhaitez probablement pas que les moteurs de recherche indexent :
- Les pages de votre site de test
- Les pages de confirmation, telles que les pages de remerciement
- Les pages d'administration ou de connexion
- Les pages de résultats de recherche internes
- Les pages avec du contenu en double
La combinaison des balises méta robots avec d'autres directives et fichiers, tels que les plans de site et les fichiers robots.txt, peut donc être un élément utile de votre stratégie de référencement technique. En effet, elles peuvent aider à prévenir les problèmes qui pourraient autrement nuire aux performances de votre site Web.
Quelles sont les spécifications de nom et de contenu pour les balises Meta Robots ?
Les balises Meta Robots contiennent deux attributs : nom et contenu. Les deux sont obligatoires.
Attribut Name
Cet attribut indique quel robot d'exploration doit suivre les instructions de la balise.
Comme ceci :
name="crawler"
Si vous souhaitez vous adresser à tous les robots d'exploration, insérez « robots » comme attribut « name ».
Comme ceci :
name="robots"
Remarque : L'attribut name n'est pas sensible à la casse. Ainsi, « robots », « ROBOTS » et « Robots » fonctionneront tous.
Si vous souhaitez limiter l'exploration à des moteurs de recherche spécifiques, l'attribut name vous permet de le faire. Et vous pouvez en choisir autant (ou aussi peu) que vous le souhaitez.
Voici quelques robots d'exploration courants :
- Google : Googlebot (ou Googlebot-news pour les résultats d'actualités)
- Bing : Bingbot (voir la liste de tous les robots d'exploration Bing)
- DuckDuckGo : DuckDuckBot
- Baidu : Baiduspider
- Yandex : YandexBot
Remarque : Bien que les principaux moteurs de recherche respectent vos balises méta-robots, il est possible que d'autres ne le fassent pas. Cela signifie que vous ne devez pas utiliser les balises méta-robots comme mesure de sécurité sur le contenu sensible. Optez plutôt pour une méthode plus sûre comme la protection par mot de passe.
Attribut de contenu
L'attribut « content » contient des instructions pour le robot d'exploration.
Il ressemble à ceci :
content="instruction"
Remarque : Comme son nom, l'attribut content n'est pas sensible à la casse.
Google prend en charge les valeurs « content » suivantes :
- Valeurs de contenu par défaut : Sans balise méta-robots, les robots d'exploration indexeront le contenu et suivront les liens par défaut (à moins que le lien lui-même ne comporte une balise « nofollow »). Cela revient à ajouter la valeur « all » suivante (bien qu'il ne soit pas nécessaire de la spécifier) :
<meta name="robots" content="all"
Ainsi, si vous ne souhaitez pas que la page apparaisse dans les résultats de recherche ou que les moteurs de recherche explorent ses liens, vous devez ajouter une balise meta robots. Avec des valeurs de contenu appropriées.
- Noindex : La valeur meta robots « noindex » indique aux robots d'exploration de ne pas inclure la page dans l'index du moteur de recherche ni de l'afficher dans les SERP.
<meta name="robots" content="noindex">
Sans la valeur noindex, les moteurs de recherche peuvent indexer et diffuser la page dans les résultats de recherche.
Les cas d'utilisation typiques de « noindex » sont les pages de panier ou de paiement sur un site Web de commerce électronique.
- Nofollow : Cela indique aux robots d'exploration de ne pas explorer les liens de la page.
<meta name="robots" content="nofollow">
Google et d'autres moteurs de recherche utilisent souvent des liens sur les pages pour découvrir ces pages liées. Et les liens peuvent aider à transmettre l'autorité d'une page à une autre.
Utilisez la règle nofollow si vous ne souhaitez pas que le robot suive les liens de la page ou leur transmette une quelconque autorité.
Cela peut être le cas si vous n'avez aucun contrôle sur les liens placés sur votre site Web. Par exemple, dans un forum non modéré avec un contenu largement généré par les utilisateurs.
Remarque : Cela n'empêche pas Google de trouver les pages liées, car elles peuvent être liées à d'autres pages et sites Web.
- Noarchive : La valeur de contenu « noarchive » indique à Google de ne pas diffuser une copie de votre page dans les résultats de recherche.
<meta name="robots" content="noarchive">
Si vous ne spécifiez pas cette valeur, Google peut afficher une copie en cache de votre page que les internautes peuvent voir dans les SERP.
Vous pouvez utiliser cette valeur pour le contenu sensible au temps, les documents internes, les pages de destination PPC ou toute autre page que vous ne souhaitez pas que Google mette en cache.
- Noimageindex : Cette valeur indique à Google de ne pas indexer les images de la page.
<meta name="robots" content="noimageindex">
L'utilisation de « noimageindex » peut nuire au trafic organique potentiel provenant des résultats d'images. Et si les utilisateurs peuvent toujours accéder à la page, ils pourront toujours trouver les images. Même avec cette balise en place.
- Notranslate : « Notranslate » empêche Google de proposer des traductions de la page dans les résultats de recherche.
<meta name="robots" content="notranslate">
Si vous ne spécifiez pas cette valeur, Google peut afficher une traduction du titre et de l'extrait d'un résultat de recherche pour les pages qui ne sont pas dans la même langue que la requête de recherche.
Utilisez cette valeur si vous préférez que votre page ne soit pas traduite par Google Translate.
Par exemple, si vous avez une page de produit avec des noms de produits que vous ne souhaitez pas traduire. Ou si vous trouvez que les traductions de Google ne sont pas toujours exactes.
- Nositelinkssearchbox : Cette valeur indique à Google de ne pas générer de champ de recherche pour votre site dans les résultats de recherche.
<meta name="robots" content="nositelinkssearchbox">
Si vous n'utilisez pas cette valeur, Google peut afficher un champ de recherche pour votre site dans les SERP.
Comme ceci :
champ de recherche sur le site « The New York Times » dans les SERP, au-dessus des liens de site
Utilisez cette valeur si vous ne souhaitez pas que le champ de recherche apparaisse.
- Nosnippet : « Nosnippet » empêche Google d'afficher un extrait de texte ou un aperçu vidéo de la page dans les résultats de recherche.
<meta name="robots" content="nosnippet">
Sans cette valeur, Google peut produire des extraits de texte ou de vidéo basés sur le contenu de la page.
La valeur « nosnippet » empêche Google d'utiliser votre contenu comme « entrée directe » pour les aperçus AI. Mais elle empêchera également les méta-descriptions, les extraits enrichis et les aperçus vidéo. Utilisez-la donc avec prudence.
Bien qu'il ne s'agisse pas d'une balise méta robots, vous pouvez utiliser l'attribut « data-nosnippet » pour empêcher l'affichage de sections spécifiques de vos pages dans les résultats de recherche.
- Max-snippet : « Max-snippet » indique à Google la longueur maximale de caractères qu'il peut afficher comme extrait de texte pour la page dans les résultats de recherche.
Cet attribut a deux cas importants à prendre en compte :
0 : exclut votre page des extraits de texte (comme avec « nosnippet »)
-1 : indique qu'il n'y a pas de limite
Par exemple, pour empêcher Google d'afficher un extrait de texte dans les SERP, vous pouvez utiliser :
<meta name="robots" content="max-snippet:0">
Ou, si vous souhaitez autoriser jusqu'à 100 caractères :
<meta name="robots" content="max-snippet:100">
Pour indiquer qu'il n'y a pas de limite de caractères :
<meta name="robots" content="max-snippet:-1">
- Max-image-preview : Cela indique à Google la taille maximale d'une image d'aperçu pour la page dans les SERP.
Il existe trois valeurs pour cette directive :
None : Google n'affichera pas d'image d'aperçu
Standard : Google peut afficher un aperçu par défaut
Large : Google peut afficher une image d'aperçu plus grande
<meta name="robots" content="max-image-preview:large">
- Max-video-preview : Cette valeur indique à Google la longueur maximale que vous souhaitez utiliser pour un extrait vidéo dans les SERP (en secondes).
Comme pour « max-snippet », il existe deux valeurs importantes pour cette directive :
0 : désactive les extraits vidéo de votre page
-1 : indique qu'il n'y a pas de limite
Par exemple, la balise ci-dessous permet à Google de diffuser un aperçu vidéo d'une durée maximale de 10 secondes :
<meta name="robots" content="max-video-preview:10">
Utilisez cette règle si vous souhaitez limiter votre extrait à certaines parties de vos vidéos. Si vous ne le faites pas, Google peut afficher un extrait vidéo de n'importe quelle longueur.
- Indexifembedded : Lorsqu'elle est utilisée avec noindex, cette balise (assez nouvelle) permet à Google d'indexer le contenu de la page s'il est intégré dans une autre page via des éléments HTML tels que des iframes.
(Elle n'aurait aucun effet sans la balise noindex.)
<meta name="robots" content="noindex, indexifembedded">
« Indexifembedded » a été créé en pensant aux éditeurs de médias :
Ils ont souvent des pages de médias qui ne doivent pas être indexées. Mais ils veulent que le média soit indexé lorsqu'il est intégré dans le contenu d'une autre page.
Auparavant, ils auraient utilisé « noindex » sur la page de média. Ce qui l'empêcherait d'être également indexé sur les pages d'intégration. « Indexifembedded » résout ce problème.
Remarque : Tous les moteurs de recherche ne prennent pas en charge cette balise.
- Unavailable_after : La valeur « unavailable_after » empêche Google d'afficher une page dans les SERP après une date et une heure spécifiques.
<meta name="robots" content="unavailable_after: 2024-10-21">
Vous devez spécifier la date et l'heure en utilisant les formats RFC 822, RFC 850 ou ISO 8601. Google ignore cette règle si vous ne spécifiez pas de date/heure. Par défaut, il n'y a pas de date d'expiration pour le contenu.
Vous pouvez utiliser cette valeur pour les pages d'événements à durée limitée, les pages sensibles au temps ou les pages que vous ne considérez plus comme importantes. Cela fonctionne comme une balise noindex temporisée, alors utilisez-la avec prudence. Vous pourriez vous retrouver avec des problèmes d'indexation plus tard.
Combinaison des règles de métabalise robots
Vous pouvez combiner les règles de métabalise robots de deux manières :
- En écrivant plusieurs valeurs séparées par des virgules dans l'attribut « contenu »
- En fournissant deux ou plusieurs métaéléments robots
Plusieurs valeurs à l'intérieur de l'attribut « Contenu »
Vous pouvez mélanger et assortir les valeurs « contenu » que nous venons de décrire. Assurez-vous simplement de les séparer par une virgule. Encore une fois, les valeurs ne sont pas sensibles à la casse.
Par exemple :
<meta name="robots" content="noindex, nofollow">
Cela indique aux moteurs de recherche de ne pas indexer la page ni d'explorer les liens de la page.
Vous pouvez combiner noindex et nofollow en utilisant la valeur « none » :
<meta name="robots" content="none">
Mais certains moteurs de recherche, comme Bing, ne prennent pas en charge cette valeur.
Remarque : Si vous combinez des directives contradictoires ou si l'une est un sous-ensemble de l'autre (comme « nosnippet, max-snippet: -1 »), Google utilisera celle qui est la plus restrictive. Dans cet exemple, la règle nosnippet s'appliquerait.
Deux ou plusieurs éléments méta robots
Utilisez des éléments méta robots distincts si vous souhaitez demander à différents robots d'exploration de se comporter différemment.
Par exemple :
<meta name="robots" content="nofollow">
<meta name="YandexBot" content="noindex">
Cette combinaison demande à tous les robots d'exploration d'éviter d'explorer les liens sur la page. Mais elle indique également à Yandex de ne pas indexer la page.
Erreurs courantes à éviter avec les balises méta-robots
Jetons un œil à certaines erreurs courantes à éviter lors de l'utilisation de balises méta-robots et de balises x-robots :
Utilisation des directives méta-robots sur une page bloquée par Robots.txt
Si vous interdisez l'exploration d'une page dans votre fichier robots.txt, les principaux robots des moteurs de recherche ne l'exploreront pas. Ainsi, toutes les balises méta-robots ou balises x-robots sur cette page seront ignorées. Assurez-vous que les moteurs de recherche peuvent explorer toutes les pages avec des balises méta-robots ou des balises x-robots.
Ajout de directives robots au fichier robots.txt
Bien que cela n'ait jamais été officiellement pris en charge par Google, vous pouviez autrefois ajouter une directive « noindex » au fichier robots.txt de votre site. Ce n'est plus une option, comme l'a confirmé Google. La règle « noindex » dans les balises méta-robots est le moyen le plus efficace de supprimer des URL de l'index lorsque vous autorisez l'exploration.
Supprimer des pages avec une directive Noindex des plans de site
Si vous essayez de supprimer une page de l'index à l'aide d'une directive « noindex », laissez la page dans votre plan de site jusqu'à ce qu'elle soit supprimée.
La suppression de la page avant sa désindexation peut entraîner des retards dans la désindexation.
Ne pas supprimer la directive « Noindex » d'un environnement de test
Empêcher les robots d'explorer les pages de votre site de test est une bonne pratique. Mais il est facile d'oublier de supprimer « noindex » une fois que le site passe en production.
Et les résultats peuvent être désastreux. Les moteurs de recherche peuvent ne jamais explorer et indexer votre site.
Pour éviter ces problèmes, vérifiez que vos balises méta robots sont correctes avant de déplacer votre site d'une plate-forme de test vers un environnement de production.
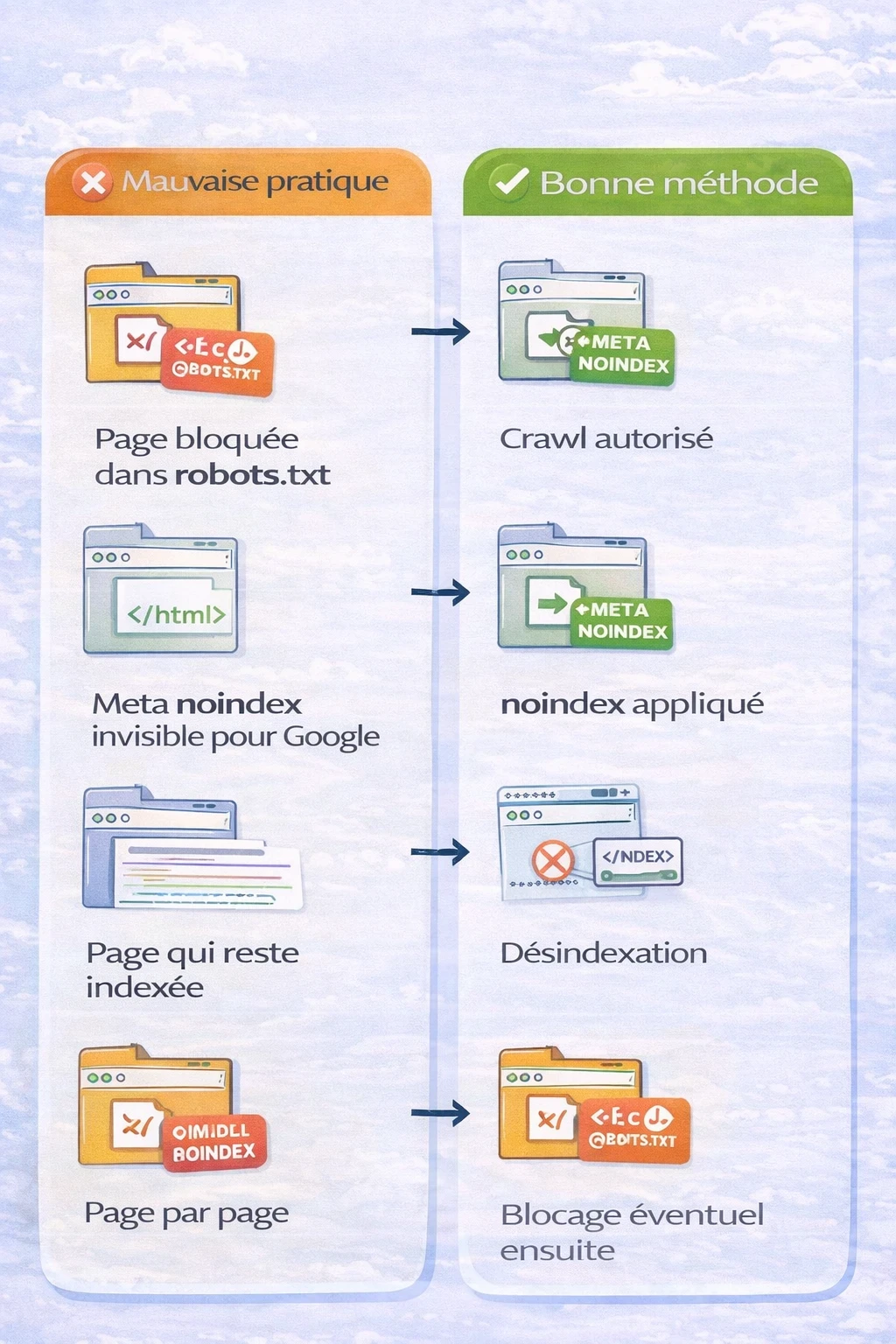
À ne JAMAIS faire avec les balises Meta Robots
- ❌ Poser un noindex sur une page bloquée dans le robots.txt
- ❌ Laisser un noindex actif après une mise en production
- ❌ Utiliser nosnippet sans comprendre son impact sur le CTR
- ❌ Bloquer des pages stratégiques (catégories, services, articles piliers)
- ❌ Multiplier les directives contradictoires “au cas où”
Retour terrain
En audit SEO, une balise noindex oubliée explique à elle seule des chutes de trafic brutales.
Ce n’est pas une erreur rare. C’est une erreur classique.
En résumé : comment utiliser les balises Meta Robots sans se tromper
- ✔️ Utilisez Meta Robots pour piloter l’indexation des pages HTML
- ✔️ Réservez X-Robots-Tag aux PDF, images et ressources serveur
- ✔️ Vérifiez toujours vos balises avant une mise en production
- ✔️ Gardez les pages en noindex dans le sitemap jusqu’à désindexation
- ✔️ Ne bloquez jamais une page critique sans intention claire
Une balise bien placée clarifie votre SEO.
Une balise mal placée peut faire disparaître un site entier des résultats.
FAQ
Noindex dangereux ?
Oui. Et plus souvent qu’on ne le croit.
Un noindex n’est pas dangereux en soi.
Ce qui l’est, c’est :
- un noindex posé par défaut,
- oublié après une mise en production,
- ou appliqué à une page stratégique.
En audit, j’ai vu des sites entiers sortir de Google pour une seule ligne de code mal placée.
Règle simple :
Si une page doit générer du trafic, elle ne doit jamais être en noindex.
X-Robots sur un PDF : utile pour le SEO ?
Oui. Et souvent indispensable.
Un PDF ne possède pas de <head>.
Donc la balise Meta Robots ne fonctionne pas.
Pour contrôler l’indexation d’un PDF, d’une image ou d’un fichier téléchargeable, X-Robots-Tag est la seule solution propre.
Cas typiques :
- documents internes,
- livres blancs,
- fiches techniques obsolètes.
Peut-on bloquer une page sans la désindexer ?
Oui, mais attention au piège.
- Disallow dans le robots.txt → empêche le crawl
- Noindex → empêche l’indexation
Bloquer une page sans la désindexer, c’est possible…
mais bloquer une page indexée empêche Google de voir le noindex.
Résultat fréquent :
- page toujours visible dans Google,
- mais impossible à nettoyer correctement.
Méthode propre :
- Autoriser le crawl
- Appliquer noindex
- Attendre la désindexation
- Bloquer si nécessaire
Meta Robots ou Robots.txt : lequel est le plus fort ?
Aucun. Ils ne font pas la même chose.
- Robots.txt = autorisation d’exploration
- Meta Robots = instruction d’indexation
Le robots.txt dit : “tu peux venir”
Meta Robots dit : “tu peux garder ou non”
Les confondre est une erreur SEO classique.
Peut-on cumuler Meta Robots et X-Robots ?
Oui, mais rarement utile.
Dans 90 % des cas :
- page HTML → Meta Robots
- ressource non HTML → X-Robots
Cumuler les deux n’apporte aucun bonus SEO.
Au contraire, ça augmente le risque d’erreur.
Une mauvaise balise robots peut-elle faire chuter un site ?
Oui. Brutalement.
Ce n’est pas une pénalité.
Ce n’est pas un filtre.
C’est pire : une disparition volontaire.
Google applique vos règles.
Même quand elles sont mauvaises.
C’est pour ça que les balises robots doivent être :
- documentées,
- vérifiées,
- contrôlées après chaque mise en ligne.
Le mot de la fin
Les balises Meta Robots et X-Robots sont des scalpels, pas des marteaux.
Bien utilisées, elles clarifient votre SEO.
Mal utilisées, elles sabotent des mois de travail, sans alerte.
En SEO, ce ne sont pas les grosses optimisations qui font mal.
Ce sont les petites lignes de code oubliées.
Si tu veux, je peux aussi te fournir :
- le schema FAQ JSON-LD optimisé SGE
- ou une version ultra-courte “Google Answer Box” prête à capter le Top 3
Prêt à concrétiser votre projet ?
Posez nous toutes vos questions et nous vous aiderons à y voir plus clair.



