
Duplicate content : comment le détecter, décider quoi indexer, et corriger sans perdre de trafic
Georges Corre Référencement
Le duplicate content, c’est le genre de sujet qui fait lever les yeux au ciel… jusqu’au jour où il plombe vraiment un site. Et là, on découvre que ce n’est pas “un détail SEO”, mais un vrai problème de contrôle : contrôle sur l’indexation, sur les pages qui rankent, sur la dilution de l’autorité, et sur le budget crawl.
Que vous soyez e-commerçant, éditeur de contenu, ou responsable d’un site vitrine, il y a une bonne nouvelle : ça se détecte vite et ça se corrige avec une méthode claire.
Dans cet article, je vous donne une approche “vieux de la vieille” : simple, pragmatique, et surtout actionnable. L’objectif : reprendre la main sur ce que Google indexe, et arrêter de laisser votre site se tirer une balle dans le pied.
Découvrez aussi notre guide SEO ou nos offres SEO.
Encart “À faire en 30 minutes”
Si vous ne voulez pas lire l'intégralité de l'article voici ce que vous pouvez réaliser en 30 minutes : assainir votre duplicate content (sans vous perdre)
- Ouvrez Google Search Console → Indexation > Pages
- Repérez les lignes du type : “Contenu en double” / “Duplicate without user-selected canonical”
- Prenez 5 URLs en exemple (2 “propres” + 3 “suspectes”) → Inspection d’URL
- Notez : Canonical déclarée vs Canonical sélectionnée (Google)
- Repérez la source du problème (en 2 minutes)
- Paramètres ?utm, ?sort, ?filter, ?color, ?size, ?page
- Tags/catégories proches, recherche interne, versions http/https, www/non-www
- Décidez quoi faire (une règle simple)
- Une seule URL doit exister → 301
- Plusieurs versions doivent rester accessibles → rel=canonical vers la page principale
- Pages sans valeur SEO (tri, recherche interne, filtres non stratégiques) → noindex
- Vérifiez la cohérence “site propre”
- Le sitemap ne contient que les URLs à indexer
- Le maillage interne pointe vers l’URL propre (pas vers des URLs à paramètres)
- Dans GSC, re-testez 1 URL : Google doit suivre votre canonical ou votre 301
Si vous ne faites que ça, vous éliminez déjà 80% des doublons les plus nocifs.
Après vous pouvez lire la suite l'article pour mieux comprendre le duplicate content et comment traiter les 20% restant.

Découvrez ces articles pour approfondir le sujet
- Analyse de fichiers journaux (logs) : l’outil SEO sous-estimé — pour repérer les URLs dupliquées que Googlebot crawl vraiment.
- Robots.txt : syntaxe, bonnes pratiques et impact SEO — utile pour cadrer l’exploration (sans confondre avec le “noindex”).
- Balises meta robots et X-Robots-Tag : explications et usages — indispensable pour gérer le noindex proprement.
- Crawl budget : les fondamentaux — pour comprendre pourquoi le duplicate content “gaspille” l’exploration.
- Plan de site XML : meilleurs outils pour créer un sitemap — pour garder un sitemap propre (uniquement les URLs à indexer).
Ce qu’est vraiment le duplicate content (et ce que Google fait en pratique)
Le duplicate content, c’est quand plusieurs URLs affichent un contenu identique ou très proche, au point que Google considère qu’elles représentent “la même chose”.
Duplicate interne vs duplicate externe
- Interne : doublons à l’intérieur de votre site (variantes, facettes, paramètres, tags, pages imprimables…).
- Externe : votre contenu est repris ailleurs (scraping, syndication), ou vous réutilisez du contenu fournisseur / un article publié sur plusieurs plateformes.
Duplicate total vs partiel
- Total : copie quasi parfaite d’une page.
- Partiel : paragraphes identiques, mêmes intros, mêmes meta titles, fiches produits clonées… souvent plus sournois.
“Google pénalise-t-il ?”
Non, pas au sens “pénalité automatique” dans la majorité des cas.
En réalité, Google choisit une version canonique (celle qu’il décide d’afficher et de classer) et ignore les autres.
Le problème, c’est que si vous ne contrôlez pas ça, Google peut :
- sélectionner la mauvaise URL (une variante ou une URL à paramètres),
- diluer vos signaux (liens, pertinence),
- et gaspiller du crawl sur des pages inutiles.
Les 12 sources de duplicate content les plus fréquentes
Je vous mets ici une liste très terrain. Si vous cochez 3 cases ou plus, vous êtes probablement concerné.
- URLs avec paramètres (UTM, tri, tracking, session)
- Facettes & filtres e-commerce (couleur, taille, marque, prix…)
- Variantes produit (taille/couleur) générées en pages distinctes
- Pagination (catégories, blog, produits)
- Catégories / tags qui répètent la même liste de contenus
- Recherche interne indexée (souvent catastrophique)
- Versions http/https, www/non-www, slash / sans slash
- Pages imprimables / PDF HTML / versions “print”
- Contenu fournisseur copié/collé (fiches produits, descriptifs standards)
- Multilingue mal géré (absence ou incohérence hreflang)
- Préprod / staging indexé par erreur
- Pages “similaires” auto-générées (plugins, modules, listings)
La plupart du temps, ce n’est pas “du plagiat”. C’est de la mécanique CMS.
Sources de duplicate content : symptômes, impacts, solutions
Source fréquente | Exemple typique | Symptôme (GSC / crawl) | Impact SEO probable | Solution recommandée |
Paramètres de tracking (UTM, ref) | /page?utm_source=facebook | URLs multiples indexées / pages “en double” | Dilution des signaux + mauvaise URL qui ranke | Laisser les UTM exister mais self-canonical sur l’URL propre + éviter le maillage interne vers URLs à paramètres |
Paramètres de tri | /categorie?sort=price_asc | Explosion d’URLs au crawl | Budget crawl gaspillé | Noindex sur tri + limiter l’exploration (maillage interne propre) |
Facettes (filtres) | /chaussures?couleur=rouge&taille=42 | Très grand volume d’URLs, faible contenu unique | Crawl budget + cannibalisation | Stratégie facettes : pages SEO dédiées à indexer, le reste noindex/canonical |
Variantes produit (couleur/taille) en pages distinctes | /produit-xyz-rouge /produit-xyz-bleu | Pages proches, titles similaires | Dilution / Google choisit la mauvaise variante | Une page principale forte + variantes canonical vers la principale (sauf variantes à intention SEO forte) |
Pagination | /categorie?page=2 | Pages paginées indexées sans valeur | Crawl sur pages faibles | Conserver l’accès UX mais éviter d’indexer les pages paginées si elles n’apportent rien (souvent noindex) |
Catégories et tags trop proches (blog) | /tag/seo/ vs /categorie/seo/ | Cannibalisation sur mêmes requêtes | Google hésite + pages faibles | Clarifier rôle : catégories utiles, tags limités ou noindex |
Pages “recherche interne” | /search?q=produit | Beaucoup d’URLs “search” | Très faible qualité perçue | Noindex + désindexation progressive |
Versions imprimables / “print” | /page?print=1 | Doublons exacts | Index pollué | Noindex ou blocage ciblé + canonical vers la page normale |
http vs https | http:// et https:// | Doublons de site | Signaux dispersés | Forcer https : 301, HSTS si possible, cohérence canonique |
www vs non-www | www.site.com vs site.com | Doublons de pages | Dilution + incohérence | Choisir une version, 301 + cohérence liens internes |
Slash vs non-slash | /page/ vs /page | Doublons au crawl | Dilution | Normaliser + 301 vers le format choisi |
Contenu fournisseur copié | Descriptions identiques à d’autres boutiques | Peu de différenciation | Difficile à positionner | Enrichir : bénéfices, usages, FAQ, avis, comparatifs, preuves |
Syndication (Medium/LinkedIn/partenaires) | Même article publié ailleurs | Risque que l’autre source ranke | Perte de contrôle | Publier d’abord chez vous + version syndiquée extraits + lien (et canonical si possible) |
Multilingue mal géré | fr/ et en/ très proches sans hreflang | Conflits entre versions | Mauvaise cible géo/langue | Implémenter hreflang + URLs propres par langue |
Préprod / staging indexée | staging.site.com indexé | Doublons massifs | Catastrophique | Bloquer via auth + noindex + retrait index + robots |
Pages “similaires” auto-générées | Plugins créant des pages duplicatives | Crawl et index “bruit” | Site “gonflé” artificiellement | Désactiver / noindex / revoir la logique de génération |
Les impacts SEO : les vrais (ceux qui font mal)
1) Vous perdez le contrôle sur la page qui ranke
Votre contenu peut être bon… mais Google choisit une URL moche (avec paramètres), ou une variante produit, ou une page de filtre.
2) Dilution de l’autorité
Si vos liens internes et externes pointent vers plusieurs URLs “équivalentes”, vous dispersez la force. Résultat : aucune URL ne devient vraiment forte.
3) Budget crawl gaspillé
Googlebot n’a pas un temps infini. S’il crawl 30 000 pages de filtres, il passe à côté de vos pages stratégiques.
4) Cannibalisation
Vous vous retrouvez avec plusieurs pages qui ciblent la même intention. Google hésite, ça bouge, ça stagne.
5) UX dégradée
Même contenu répété, même promesse, mêmes paragraphes : l’utilisateur tourne en rond.

Détecter le duplicate content en 20 minutes : méthode simple
Je vous donne un process court, efficace, sans blabla.
Étape 1 — Google Search Console : repérer les duplications “officielles”
Dans GSC :
- Pages → regardez les exclusions et alertes du type :
- “Contenu en double : Google a choisi une autre URL canonique”
- “Duplicate without user-selected canonical”
Objectif : identifier les familles d’URLs qui posent problème (paramètres, facettes, tags, pagination…).
Étape 2 — Inspection d’URL : comprendre la canonical choisie par Google
Prenez 3 à 5 URLs concernées. Dans l’inspection :
- Canonical déclarée (par vous)
- Canonical sélectionnée (par Google)
Si Google ne suit pas votre canonical, c’est qu’il détecte des signaux contradictoires.
Étape 3 — Crawl (Screaming Frog ou équivalent)
Analysez :
- Titles identiques
- Meta descriptions identiques
- H1 identiques
- Contenus proches
- Canonicals absentes / incohérentes
Étape 4 — Vérifier les paramètres d’URL qui explosent
Regardez vos patterns :
- ?sort=
- ?filter=
- ?color=
- ?size=
- ?page=
- ?utm_source=
Si vous voyez des combinaisons infinies, vous avez un chantier facettes.
Étape 5 — Duplicate externe (si pertinent)
- Copyscape (ou équivalent)
- recherche de phrases exactes entre guillemets (simple mais utile)
Étape 6 — Logs serveur (bonus pro)
Si vous avez accès aux logs :
- quelles URLs Googlebot crawl le plus ?
- où il gaspille ?
- quelles pages stratégiques sont peu crawlées ?
C’est souvent là que la vérité sort.
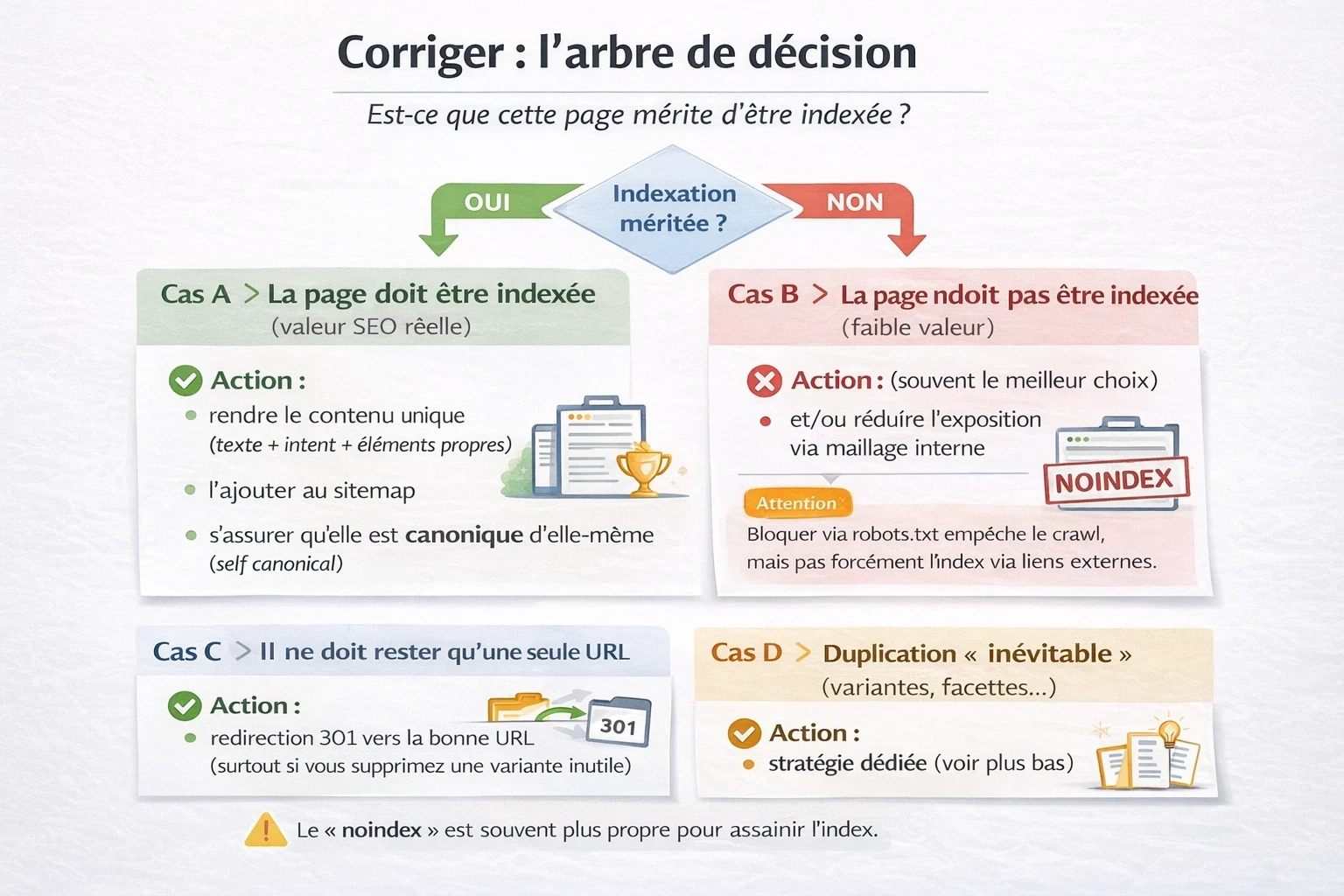
Corriger : l’arbre de décision (le cœur du sujet)
Avant de “corriger”, posez-vous LA question :
Est-ce que cette page mérite d’être indexée ?
Cas A — La page doit être indexée (valeur SEO réelle)
✅ Action :
- rendre le contenu unique (texte + intent + éléments propres)
- renforcer le maillage interne vers cette version
- l’ajouter au sitemap
- s’assurer qu’elle est canonique d’elle-même (self canonical)
Cas B — La page ne doit pas être indexée (faible valeur)
✅ Action :
- noindex (souvent le meilleur choix)
- et/ou réduire l’exposition via maillage interne
Attention : bloquer via robots.txt empêche le crawl, mais n’enlève pas forcément une URL déjà indexée si elle est découverte via liens externes. Le “noindex” est souvent plus propre pour assainir l’index.
Cas C — Il ne doit rester qu’une seule URL
✅ Action :
- redirection 301 vers la bonne URL (surtout si vous supprimez une variante inutile)
- nettoyer les liens internes qui pointent vers l’ancienne
Cas D — Duplication “inévitable” (variantes, facettes…)
✅ Action :
- stratégie dédiée (voir plus bas)
Cas n°1 : e-commerce — variantes produit et facettes (la zone de guerre)
Si vous faites de l’e-commerce, je vous le dis franchement :
le duplicate content n’est pas un bug, c’est une conséquence normale du fonctionnement des catalogues.
L’enjeu, ce n’est pas “zéro duplicate”.
L’enjeu, c’est : indexation propre + pages qui rankent volontairement.
Variantes taille/couleur : faut-il indexer ?
Règle simple :
- Indexez une variante uniquement si elle répond à une intention de recherche spécifique et rentable (ex : “chaussures rouges cuir”, “robe lin grande taille”).
- Sinon : canonical vers la fiche principale.
Ce que je vise :
- 1 page forte = 1 produit principal (ou 1 intention)
- des variantes gérées sans disperser la force
Facettes & filtres : ce que je fais (pragmatique)
- Je n’indexe pas des combinaisons infinies du type :
- “marque + couleur + taille + prix + disponibilité + livraison…”
- Je garde :
- quelques facettes “métier” utiles (marque, catégorie, type) si elles ont un volume et une intention claire
- Je crée des pages SEO dédiées (landing pages facettes) quand la requête est stratégique :
- “t-shirt bio homme”
- “chaussures de sécurité S3”
- “robe invitée mariage”
Ces pages-là :
- ont un contenu éditorial propre
- un maillage interne propre
- une indexation assumée
La règle d’or sur les facettes (par Laurent Lacoste)
Moi, quand je vois une boutique avec 12 filtres, je sais déjà ce qui va se passer :
Google va découvrir une infinité d’URLs… et votre serveur va faire de la muscu.
Mon approche :
- Limiter la combinatoire (règles côté front / back)
- Normaliser les URLs (un format propre, pas 15 versions)
- Décider ce qu’on indexe :
- pages SEO dédiées → index
- le reste → noindex / canonical / pas de lien interne
Et surtout : on évite le “tout indexer et on verra”. On voit… mais après c’est trop tard.
Cas n°2 : blog / site vitrine — le duplicate “invisible”
Sur un blog, les coupables sont souvent :
- tags et catégories trop proches
- archives paginées
- pages auteur
- pages de recherche interne
- contenus recyclés (mêmes paragraphes partout)
Mes règles simples
- Une catégorie = une vraie page utile (intro unique + logique édito)
- Les tags : soit je les structure très bien, soit je désindexe
- Recherche interne : souvent noindex
- Pages auteur : utile si vous jouez l’EEAT (sinon, à surveiller)
Canonical : ce qu’il faut savoir pour ne pas se tromper
La balise canonical sert à dire : “cette page est une variante, l’originale est celle-ci”.
Mais attention : Google peut ne pas la suivre si vos signaux disent l’inverse.
Les signaux qui pèsent (et qui peuvent contredire)
- redirections
- maillage interne
- sitemap
- cohérence des URLs
- contenu réellement similaire ou non
Mon conseil :
- self-canonical sur les pages que vous voulez indexer
- canonical vers la page principale pour les variantes
- cohérence partout (liens internes + sitemap + canonicals)
5 erreurs de canonical que je vois tout le temps (par Laurent)
- Canonical vers une page en 404 (oui, ça arrive…)
- Canonical vers une page bloquée / noindex
- Canonical incohérentes entre desktop/mobile ou langues
- Canonical en pagination mal gérée
- Canonical mise “au hasard” sur des pages pas vraiment similaires
Bref : la canonical, c’est pas un pansement magique. C’est une déclaration. Et Google vérifie si vous êtes cohérent.
“Duplicate without user-selected canonical” : pourquoi ça arrive et quoi faire
Quand GSC affiche ça, Google vous dit :
“j’ai trouvé des doublons, et vous ne m’avez pas aidé (ou pas assez).”
Causes fréquentes
- pas de canonical
- canonicals contradictoires
- paramètres d’URL non maîtrisés
- pages proches mais pas identiques
- maillage interne qui pointe sur une URL “variante”
Plan d’action rapide
- Choisir la bonne URL canonique
- Mettre en place :
- self canonical sur la bonne page
- canonical / 301 / noindex sur les variantes
- Nettoyer le maillage interne
- Vérifier le sitemap (ne garder que les URLs à indexer)
- Contrôler dans l’inspection d’URL que Google suit
Duplicate without user-selected canonical” : cause → fix → vérification
Symptôme (GSC / Inspection) | Cause la plus fréquente | Correctif prioritaire | Comment vérifier |
“Duplicate without user-selected canonical” | Aucune canonical déclarée (ou incohérente) | Mettre self-canonical sur la page à indexer + canonical sur variantes | Inspection d’URL : “Canonical déclarée” = “Canonical sélectionnée” |
Google choisit une autre canonical que vous | Signaux contradictoires (liens internes, sitemap, redirections) | Aligner : maillage interne → URL cible, sitemap → URL cible, corriger redirections | Crawl + inspection : Google suit la version voulue |
URLs à paramètres indexées (tri / filtres) | Facettes non maîtrisées + maillage vers URLs filtrées | Noindex sur tri/filtres non stratégiques + pages SEO dédiées | GSC : baisse des URLs “en double” + crawl réduit |
Plusieurs URLs “techniques” pour la même page | www/non-www, slash, http/https | Normalisation + 301 partout | Crawl : 1 seule version retournant 200, le reste en 301 |
Pages paginées “en double” | Pagination sans valeur unique | Noindex (si pertinent) + enrichir page 1 + maillage vers page 1 | GSC : pages paginées sortent progressivement de l’index |
Contenu similaire entre catégories/tags | Taxonomies trop proches | Désindexer tags faibles ou différencier fortement les pages | GSC : moins de cannibalisation, requêtes stabilisées |
Canonical vers une page non équivalente | Canonical utilisée “comme un pansement” | Ne canoniser que des pages réellement proches + préférer 301 quand c’est un remplacement | Inspection : canonical logique + cohérence du contenu |
Canonical vers une URL bloquée/noindex/404 | Erreur technique | Corriger la cible canonical + réparer statut 200 | Crawl : canonical cible = 200, indexable |
Checklist finale : assainir l’indexation
- Une seule version du site (https, www/non-www, slash)
- Pas de préprod indexée
- Pages de recherche interne en noindex
- Facettes : stratégie claire (pages SEO vs noindex/canonical)
- Variantes produit : indexées seulement si intention spécifique
- Canonical cohérentes (self canonical sur pages importantes)
- Titles / metas non dupliqués sur pages stratégiques
- Sitemap nettoyé : uniquement URLs à indexer
- Maillage interne aligné sur les pages “à ranker”
- GSC : surveillance des statuts “duplication”
- Crawl régulier (mensuel sur e-commerce)
- Logs : vérifier le gaspillage crawl (si possible)
Comme toutes les listes que nous fournissons, il faut surveiller tous ces points et faire le check tous les 6 mois ou au moins tous les ans.
Que retenir ?
Le duplicate content n’est pas une fatalité. C’est souvent un effet secondaire normal d’un site vivant (e-commerce, blog, CMS). La différence entre un site qui stagne et un site qui progresse, c’est une chose : la capacité à décider ce qui doit être indexé… et à être cohérent partout (canonical, redirections, maillage, sitemap).
Si vous appliquez la méthode de détection + l’arbre de décision, vous reprenez la main. Et Google, lui, adore quand on lui simplifie le travail.
Et si vous voulez en parler avec des spécialistes, contactez nous.
FAQ duplicate content
Google pénalise-t-il le duplicate content ?
En général, non : il choisit une version et ignore les autres. Le vrai risque, c’est de perdre le contrôle.
Canonical ou redirection 301 ?
- 301 si vous voulez remplacer définitivement une URL
- canonical si vous devez garder plusieurs URLs accessibles (variantes) mais concentrer les signaux
Noindex ou robots.txt ?
- noindex pour retirer proprement de l’index
- robots.txt pour empêcher le crawl (mais pas idéal pour “nettoyer” l’index)
Les UTM créent-ils du duplicate content ?
Oui, techniquement. En pratique, il faut éviter que ces URLs soient maillées/interne indexables, et privilégier une URL canonique propre.
Peut-on utiliser du contenu fournisseur ?
Vous pouvez, mais c’est rarement un bon plan SEO. Au minimum : enrichir, structurer, ajouter valeur et différenciation.
Prêt à concrétiser votre projet ?
Posez nous toutes vos questions et nous vous aiderons à y voir plus clair.



