
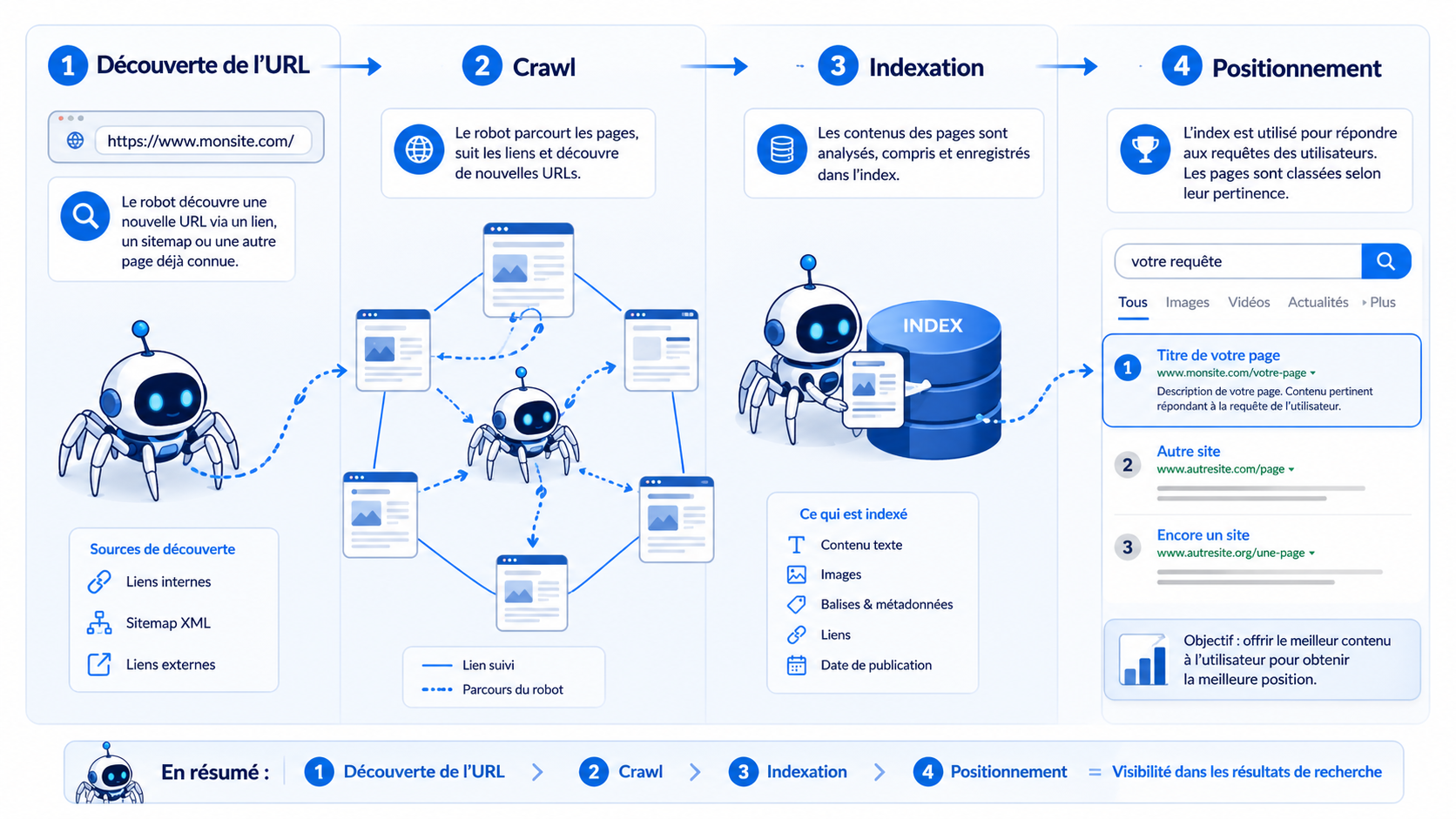
Le crawl est l’une des premières étapes du référencement naturel. Avant qu’une page puisse apparaître dans Google, elle doit d’abord être découverte, visitée et analysée par les robots des moteurs de recherche. C’est cette étape que l’on appelle le crawl.
Dans mes formations SEO, je vois souvent la même confusion : une page publiée en ligne serait automatiquement visible sur Google. En réalité, les choses sont plus progressives. Google doit d’abord trouver la page, l’explorer, décider s’il peut l’indexer, puis éventuellement la positionner sur une requête.
Comprendre le crawl permet donc de mieux comprendre pourquoi certaines pages restent invisibles, pourquoi une refonte peut faire perdre du trafic, ou pourquoi un site bien rédigé peut malgré tout manquer de visibilité.
Définition simple du crawl en SEO
Le crawl désigne l’exploration d’un site web par un robot de moteur de recherche. Pour Google, ce robot s’appelle Googlebot. Son rôle est de parcourir le web, de visiter des pages, de lire leur contenu et de suivre les liens qu’il trouve.
Google explique que son moteur utilise des programmes automatisés, appelés crawlers, pour explorer le web et trouver des pages à ajouter à son index. La majorité des sites présents dans les résultats Google sont découverts automatiquement, sans demande manuelle du propriétaire du site.
Pour faire simple : le crawl, c’est la visite. Googlebot arrive sur une URL, récupère ce qu’il peut lire, suit certains liens, puis transmet ces informations aux systèmes de Google.
Le crawl ne garantit pas qu’une page sera indexée. Il ne garantit pas non plus qu’elle sera bien positionnée. C’est une étape nécessaire, mais ce n’est que le début du processus SEO.
Référence utile : documentation Google sur le fonctionnement de la recherche .
Crawl, indexation, positionnement : trois étapes à ne pas confondre
En SEO, on mélange souvent ces trois notions. Pourtant, elles ne veulent pas dire la même chose.
| Étape | Définition simple | Exemple concret |
|---|---|---|
| Crawl | Googlebot visite la page. | Google découvre une nouvelle page service grâce à un lien interne. |
| Indexation | Google analyse la page et décide de l’ajouter ou non à son index. | La page peut être stockée dans l’index, ou rester en “explorée, non indexée”. |
| Positionnement | Google affiche la page dans les résultats selon une requête. | La page apparaît en 3e, 8e ou 25e position sur un mot-clé. |
Cette distinction est importante. Une page peut être crawlée sans être indexée. Elle peut aussi être indexée sans générer de trafic, parce qu’elle est mal positionnée ou qu’elle ne répond pas assez bien à l’intention de recherche.
Si vous voyez dans Google Search Console une URL indiquée comme “explorée, actuellement non indexée”, le problème ne vient pas forcément d’un blocage technique. Il peut venir de la qualité du contenu, du maillage interne, de la profondeur de la page ou de sa proximité avec d’autres pages similaires.
À lire aussi sur le blog : Référencement : que faire lorsqu’une page est explorée mais non indexée par Google ?
Que regarde Google pendant le crawl ?
Pendant le crawl, Googlebot récupère plusieurs éléments de la page. Il peut lire le code HTML, le texte, les liens, les images, certaines ressources techniques, les balises et les signaux envoyés par le serveur.
Dans certains cas, Google peut aussi rendre la page, c’est-à-dire l’interpréter comme un navigateur. C’est important pour les sites qui utilisent beaucoup JavaScript pour afficher leurs contenus.
Googlebot regarde notamment :
- le contenu visible de la page ;
- les liens présents dans la page ;
- les balises title et meta description ;
- les balises robots ;
- les liens canoniques ;
- les codes de réponse HTTP ;
- les images et leurs attributs ;
- les ressources nécessaires au rendu ;
- les données structurées, si elles existent.
C’est pour cela qu’un audit SEO ne doit pas se limiter aux mots-clés. Il faut aussi vérifier si les pages importantes sont accessibles, lisibles et compréhensibles par les moteurs de recherche.
Référence utile : documentation Google sur Googlebot .
Pourquoi le crawl est important pour le SEO ?
Le crawl est important parce qu’il conditionne tout le reste. Si Google ne découvre pas correctement vos pages, il ne peut pas les analyser correctement. Et s’il ne les analyse pas correctement, elles auront peu de chances de se positionner.
C’est particulièrement sensible dans plusieurs cas :
- un site e-commerce avec beaucoup de catégories, filtres et produits ;
- un blog qui publie régulièrement de nouveaux contenus ;
- un site Joomla ou WordPress avec une arborescence ancienne ;
- une refonte avec des redirections mal préparées ;
- un site qui contient beaucoup de pages proches ou dupliquées ;
- un site lent ou instable côté serveur.
Dans ces situations, Google peut passer du temps sur des URL peu utiles au lieu d’explorer les pages qui ont une vraie valeur SEO. On peut alors publier beaucoup de contenu sans obtenir les résultats attendus.
À lire aussi : Crawl budget : les fondamentaux
Ce qui peut bloquer ou ralentir le crawl
Un mauvais crawl vient rarement d’un seul problème. Il s’agit souvent d’un ensemble de petits défauts : une structure confuse, des liens internes insuffisants, des pages inutiles, des erreurs serveur, des redirections mal gérées ou un fichier robots.txt trop restrictif.
Un fichier robots.txt mal configuré
Le fichier robots.txt indique aux robots les URL qu’ils peuvent ou ne peuvent pas explorer. Il peut être utile pour éviter que les moteurs passent trop de temps sur certaines zones techniques.
Mais il faut l’utiliser avec prudence. Google rappelle qu’un fichier robots.txt n’est pas le bon outil pour empêcher une page d’apparaître dans les résultats. Pour empêcher l’indexation, il faut plutôt utiliser une balise noindex ou protéger la page par mot de passe.
À lire aussi : Robots.txt expliqué simplement : syntaxe, bonnes pratiques et impact SEO
Référence utile : documentation Google sur robots.txt .
Des pages trop profondes
Une page accessible en un ou deux clics depuis une page importante sera généralement plus facile à découvrir qu’une page cachée au fond du site.
La profondeur d’une page n’est pas seulement une question de confort utilisateur. C’est aussi un signal de structure. Si une page est importante, elle doit être reliée depuis des zones fortes du site.
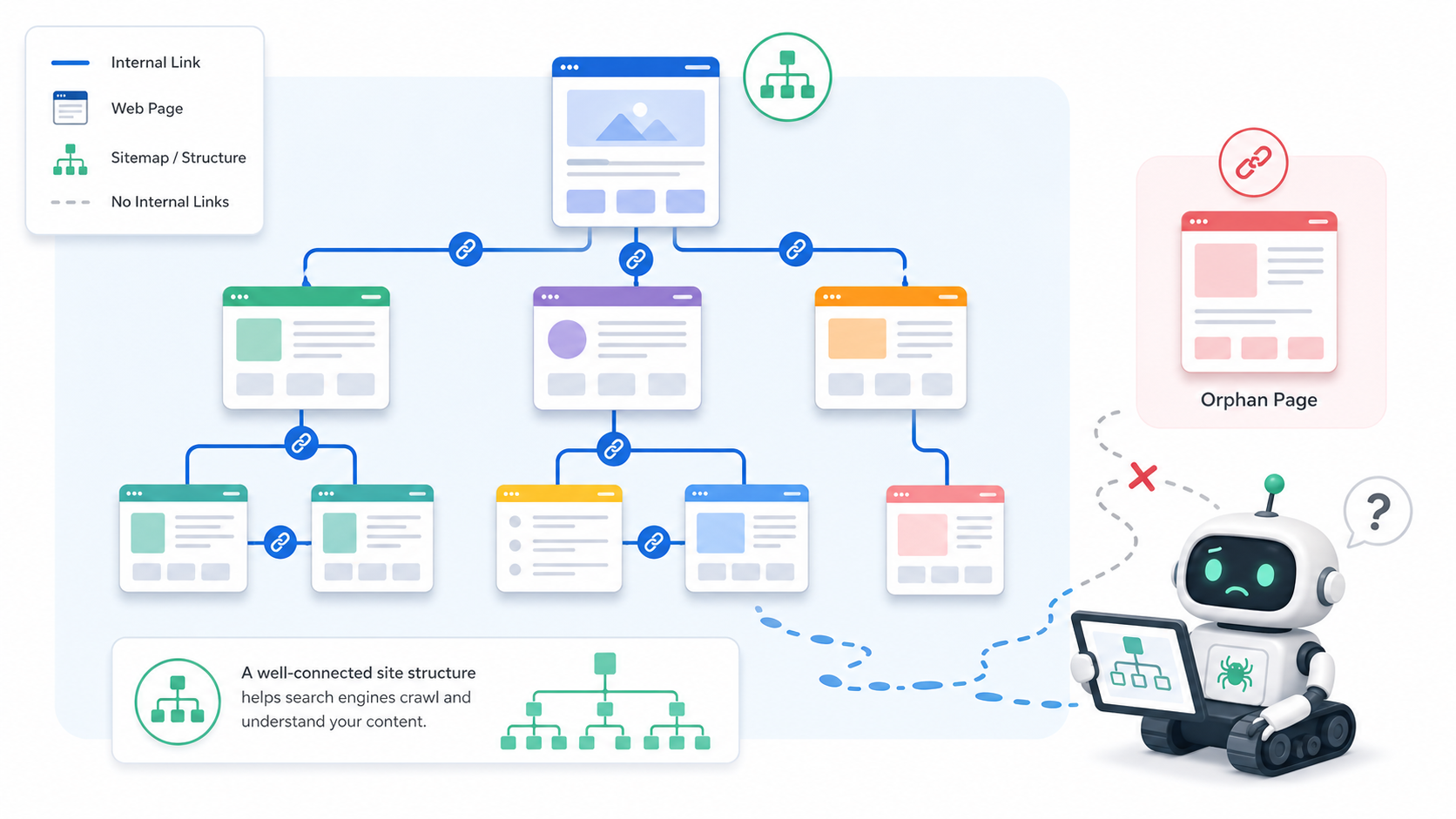
Un maillage interne insuffisant
Une page sans lien interne est une page orpheline. Elle peut exister, mais elle n’est pas correctement intégrée au site.
Le maillage interne aide Google à découvrir les pages, à comprendre leur rôle et à identifier les contenus prioritaires. C’est aussi un levier essentiel dans une stratégie de cocon sémantique.
À lire aussi : Cocon sémantique : boîte à outils pour mieux structurer vos contenus
Des erreurs techniques
Les erreurs 404, les erreurs 500, les redirections en chaîne ou les pages très lentes peuvent perturber l’exploration.
Googlebot tient compte des réponses serveur. Si un site répond mal ou trop lentement, l’exploration peut devenir moins efficace.
À lire aussi : Refonte SEO : redirections, sitemaps et points de vigilance
Trop de pages inutiles
Certains sites génèrent beaucoup d’URL à faible valeur : filtres, tags, archives, résultats de recherche interne, paramètres d’URL ou variantes de tri.
Sur un petit site, ce n’est pas toujours bloquant. Sur un gros site e-commerce ou un blog ancien, cela peut devenir un vrai sujet.
| Problème | Conséquence SEO | Action corrective |
|---|---|---|
| Page orpheline | Google la découvre mal ou tardivement. | Ajouter des liens internes depuis des pages fortes. |
| Robots.txt trop restrictif | Googlebot ne peut pas explorer certaines URL. | Vérifier les directives bloquantes. |
| Redirections en chaîne | Le crawl devient moins efficace. | Simplifier les redirections vers l’URL finale. |
| Pages lentes | L’exploration peut être moins fluide. | Optimiser les images, le cache et le serveur. |
| Sitemap obsolète | Google reçoit de mauvais signaux de découverte. | Mettre à jour le sitemap XML. |
Crawl budget : faut-il vraiment s’en préoccuper ?
Le crawl budget correspond, de manière simplifiée, au volume de pages qu’un moteur peut ou souhaite explorer sur un site pendant une période donnée.
Pour un site vitrine de quelques dizaines de pages, ce n’est généralement pas le premier problème. Il vaut mieux commencer par des bases solides : une arborescence claire, des pages utiles, un bon maillage interne, un sitemap propre et des performances correctes.
En revanche, le crawl budget devient plus important pour :
- les sites e-commerce avec beaucoup de produits ;
- les sites avec des filtres et facettes ;
- les gros blogs anciens ;
- les sites avec beaucoup de contenus dupliqués ;
- les sites ayant connu plusieurs refontes ;
- les plateformes avec des milliers d’URL.
Dans ces cas, il faut éviter de gaspiller l’exploration sur des URL sans intérêt. L’objectif est simple : aider Google à passer plus de temps sur les pages qui comptent vraiment.
Comment savoir si Google crawle bien votre site ?
Plusieurs outils permettent de vérifier si Google explore correctement vos pages.
Google Search Console
Google Search Console est l’outil de base. Il permet de suivre l’indexation, de consulter les problèmes détectés et d’inspecter une URL précise.
L’outil d’inspection d’URL permet notamment de savoir ce que Google connaît d’une page, si elle est indexable, si elle présente des problèmes et si une demande d’exploration peut être envoyée.
Référence utile : documentation Google sur l’outil d’inspection d’URL .
Le sitemap XML
Le sitemap XML aide à signaler les URL importantes. Il ne garantit pas l’indexation, mais il facilite la découverte des pages.
À lire aussi : Les meilleurs outils pour créer un plan de site XML
Les fichiers journaux
Les fichiers journaux, ou logs serveur, montrent les visites réelles des robots sur le site. C’est une donnée précieuse, car elle ne repose pas sur une estimation.
Avec une analyse de logs, on peut savoir quelles pages Googlebot visite, à quelle fréquence, quelles erreurs il rencontre et quelles zones du site il ignore.
À lire aussi : Analyse de fichiers journaux : l’outil SEO sous-estimé qui dit la vérité sur votre site
Les crawlers SEO
Des outils comme Screaming Frog, Sitebulb ou Oncrawl permettent de simuler l’exploration d’un site. Ils aident à repérer les erreurs, les pages orphelines, les redirections, les balises manquantes ou les problèmes de profondeur.
Ces outils ne remplacent pas Google Search Console ni les logs serveur, mais ils donnent une vision très utile de la structure technique du site.
Les bonnes pratiques pour faciliter le crawl
Un bon crawl commence par un site propre, cohérent et facile à parcourir. Il ne s’agit pas de chercher une astuce magique, mais de rendre le travail des moteurs plus simple.
- Construire une arborescence claire.
- Relier les pages importantes depuis les menus, les pages piliers et les articles associés.
- Éviter les pages orphelines.
- Mettre à jour le sitemap XML.
- Corriger les erreurs 404 utiles à corriger.
- Limiter les redirections inutiles.
- Éviter de bloquer par erreur les pages importantes dans robots.txt.
- Utiliser noindex pour les pages qui ne doivent pas être indexées.
- Optimiser les performances techniques.
- Surveiller les logs serveur sur les sites à fort volume d’URL.
Pour les sites Joomla, WordPress, Prestashop ou WooCommerce, ces points sont souvent liés au thème, aux extensions, aux filtres, aux catégories et aux réglages SEO du CMS.
À lire aussi : Optimiser un site Joomla pour le SEO et Prestashop SEO : guide complet pour optimiser votre boutique .
Référence utile : documentation Google sur la balise noindex .
Exemple concret : une page publiée mais invisible sur Google
Prenons un cas simple. Une entreprise publie une nouvelle page service. Le texte est correct, le sujet est intéressant, mais la page ne génère aucun trafic après plusieurs semaines.
En analysant la situation, on découvre plusieurs problèmes :
- la page n’est liée depuis aucune page importante ;
- elle n’apparaît pas dans le menu ;
- elle n’est pas présente dans le sitemap XML ;
- elle se trouve à plusieurs clics de la page d’accueil ;
- aucun article de blog ne fait de lien vers elle.
Dans ce cas, le problème ne vient pas seulement du contenu. Il vient aussi de l’accès à la page. Elle existe, mais elle n’est pas assez intégrée dans le site.
La correction peut être assez simple :
- ajouter un lien depuis une page pilier ;
- créer un lien depuis un article de blog proche du sujet ;
- ajouter la page au sitemap ;
- vérifier son indexabilité dans Google Search Console ;
- améliorer son contenu si elle est trop proche d’une autre page existante.
C’est souvent ce type de détail qui fait la différence entre une page publiée et une page réellement visible.
Quand faut-il faire un audit de crawl ?
Un audit de crawl devient utile lorsque le site publie beaucoup, change souvent ou présente des signes de blocage.
Je recommande de l’envisager dans plusieurs situations :
- après une refonte ;
- avant une migration de CMS ;
- lorsqu’un site perd du trafic sans raison évidente ;
- lorsque beaucoup de pages restent non indexées ;
- lorsqu’un site e-commerce possède beaucoup de filtres ;
- lorsqu’un blog ancien contient des centaines d’articles.
Chez TooNetCreation, un audit SEO technique permet de vérifier si les pages importantes sont accessibles, bien maillées, correctement indexables et cohérentes avec les objectifs de visibilité.
À lire aussi : Pourquoi faire un audit SEO ? et Combien coûte un audit SEO ?
À retenir
Le crawl est la première étape du référencement naturel. Avant de parler de positionnement, de backlinks ou de conversions, il faut s’assurer que Google peut découvrir et explorer les bonnes pages.
Une page publiée n’est pas automatiquement visible. Elle doit être accessible, reliée, lisible et indexable. Le sitemap, le maillage interne, les performances, les redirections, les balises robots et les logs serveur jouent tous un rôle dans cette mécanique.
Pour un petit site, l’objectif est surtout de garder une structure simple et propre. Pour un site plus volumineux, le crawl devient un vrai levier d’optimisation SEO.
Si votre site publie régulièrement des contenus mais que certaines pages restent invisibles sur Google, un audit SEO peut aider à comprendre si le problème vient du contenu, de l’indexation, du maillage ou de l’exploration.
FAQ sur le crawl SEO
Quelle est la différence entre crawl et indexation ?
Le crawl correspond à la visite d’une page par Googlebot. L’indexation correspond à l’analyse et à l’ajout éventuel de cette page dans l’index de Google. Une page peut donc être crawlée sans être indexée.
Google crawle-t-il toutes les pages d’un site ?
Non. Google peut ne pas explorer toutes les pages, surtout si certaines sont peu accessibles, bloquées, très profondes, dupliquées ou jugées peu utiles.
Combien de temps faut-il pour qu’une page soit crawlée ?
Il n’existe pas de délai garanti. Une page bien maillée, présente dans le sitemap et publiée sur un site actif peut être découverte plus rapidement qu’une page isolée.
Le sitemap XML garantit-il le crawl ?
Non. Le sitemap aide Google à découvrir des URL importantes, mais il ne garantit ni le crawl, ni l’indexation, ni le positionnement.
Le fichier robots.txt empêche-t-il une page d’apparaître dans Google ?
Pas toujours. Le fichier robots.txt sert surtout à contrôler l’exploration. Pour empêcher l’indexation d’une page, Google recommande plutôt l’utilisation d’une balise noindex ou une protection par mot de passe.
Comment voir si Google a crawlé une page ?
Vous pouvez utiliser l’outil d’inspection d’URL dans Google Search Console. Pour une analyse plus précise, les fichiers journaux permettent de voir les passages réels de Googlebot sur le serveur.
Faut-il un outil payant pour analyser le crawl ?
Pas forcément. Google Search Console donne déjà des informations utiles. En revanche, pour les sites volumineux, un crawler SEO et une analyse de logs apportent une vision plus complète.




Comment Googlebot découvre les pages d’un site ?
Googlebot ne visite pas les pages au hasard. Il découvre les URL à partir de plusieurs sources.
Le maillage interne joue donc un rôle très concret. Une page bien reliée depuis l’accueil, une page pilier ou un article important sera plus facile à découvrir qu’une page isolée.
À lire aussi : Netlinking interne : les erreurs courantes qui ruinent vos efforts SEO