
Vous avez publié une page, Google l’a bien explorée, mais elle reste absente de son index ? Dans Google Search Console, le message « Explorée, actuellement non indexée » peut vite devenir frustrant. La page existe, elle est accessible, elle a été vue par Googlebot… mais elle ne ressort pas dans les résultats.
Je vois souvent ce problème dans les audits SEO. Et, très honnêtement, il ne faut pas toujours chercher une panne technique spectaculaire. Parfois, Google a simplement regardé la page et n’a pas trouvé de raison suffisante pour la garder dans son index.
Je travaille sur le web depuis assez longtemps pour avoir vu passer plusieurs « révolutions définitives ». L’intelligence artificielle en est une vraie, bien sûr. Dans mes études d’ingénieur, l’IA n’était déjà pas un simple gadget à la mode. Mais aujourd’hui, avec la production massive de contenus assistés par IA, un vieux principe SEO redevient central : publier une page ne veut pas dire que Google va l’indexer.
Que signifie « Explorée, actuellement non indexée » dans Google Search Console ?
Dans le rapport d’indexation de Google Search Console, le statut « Explorée, actuellement non indexée » signifie que Google a bien crawlé la page, mais qu’il ne l’a pas ajoutée à son index.
C’est un point important : Google connaît la page. Il a pu y accéder. Il l’a analysée. Mais, à ce stade, il ne la retient pas dans sa base de résultats.
La documentation officielle de Google précise que ce statut peut évoluer, mais qu’il n’est pas nécessaire de renvoyer systématiquement l’URL pour exploration. Autrement dit, le bouton « Demander une indexation » ne règle pas tout. Si la page ne convainc pas Google, la redemander telle quelle revient souvent à présenter deux fois le même dossier insuffisant.
Source officielle : Google Search Console — Rapport d’indexation des pages
| Statut dans Search Console | Ce que cela signifie | Niveau d’attention |
|---|---|---|
| Découverte, actuellement non indexée | Google connaît l’URL, mais ne l’a pas encore explorée. | À surveiller, surtout si la situation dure. |
| Explorée, actuellement non indexée | Google a exploré la page, mais ne l’a pas indexée. | À diagnostiquer en priorité si la page est stratégique. |
| Dupliquée, Google a choisi une autre canonique | Google considère qu’une autre URL représente mieux le contenu. | À analyser, surtout en e-commerce ou sur les sites avec variantes. |
| Exclue par une balise noindex | La page demande explicitement à ne pas être indexée. | Normal si c’est volontaire, problématique sinon. |
| Bloquée par robots.txt | Googlebot ne peut pas explorer la page. | Problématique si la page doit être visible dans Google. |
À retenir : une page explorée n’est pas automatiquement une page indexée. C’est souvent là que commence le vrai diagnostic SEO.
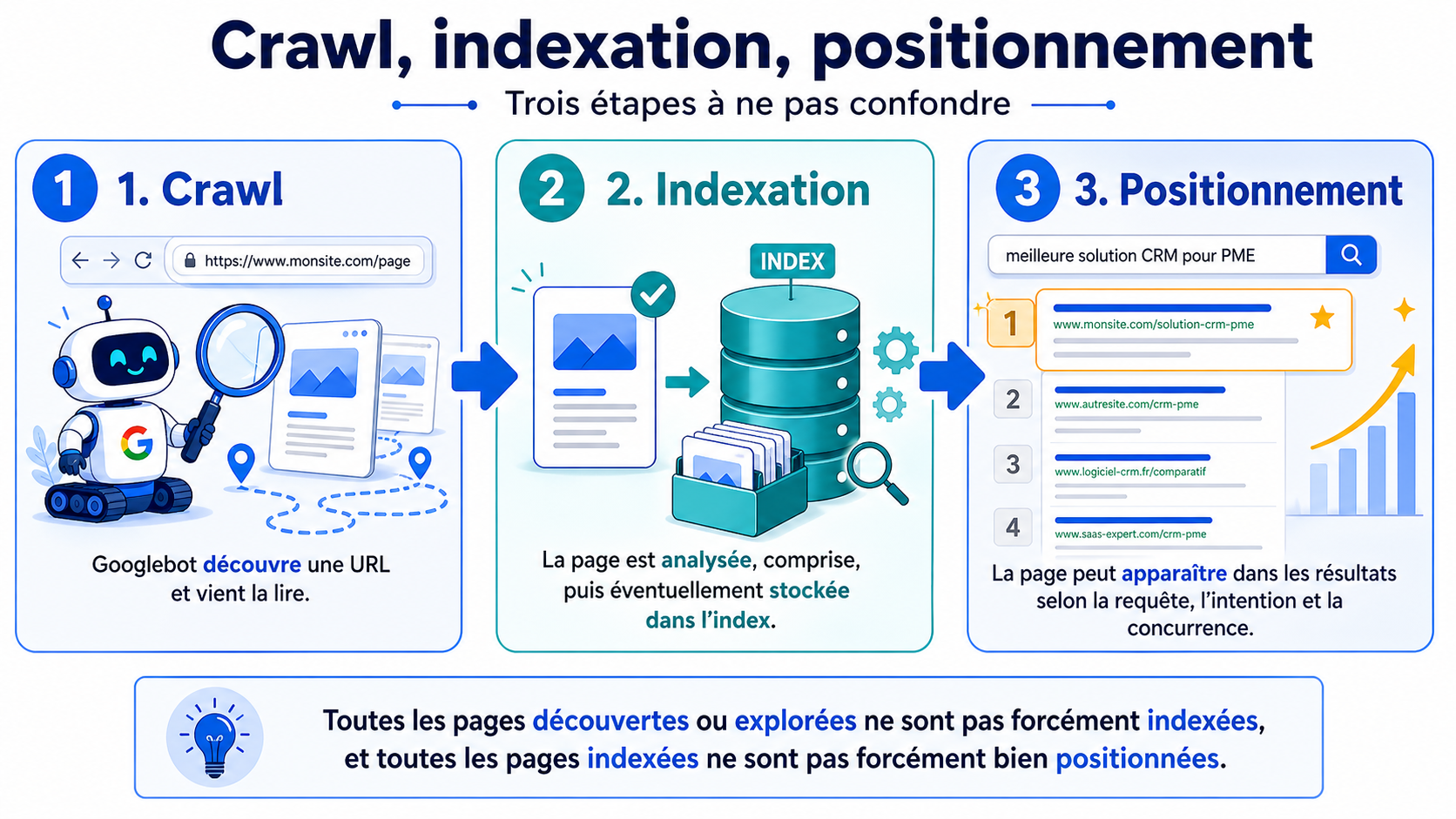
Crawl, indexation, positionnement : trois étapes à ne pas confondre
Dans beaucoup de discussions SEO, on mélange encore trop souvent trois notions différentes : le crawl, l’indexation et le positionnement.
Le crawl, c’est la visite. Googlebot découvre une URL et vient la lire.
L’indexation, c’est l’entrée dans la base de Google. La page est analysée, comprise, puis éventuellement stockée dans l’index.
Le positionnement, c’est l’affichage de cette page dans les résultats, selon une requête précise, une intention, une concurrence et de nombreux signaux de qualité.
Google explique officiellement que son moteur fonctionne en grandes étapes : exploration, indexation, puis diffusion des résultats. Toutes les pages découvertes ou explorées ne franchissent pas forcément toutes ces étapes.
Source officielle : Google Search Central — Fonctionnement de la recherche Google
| Étape | Ce que fait Google | Ce que cela signifie pour vous |
|---|---|---|
| Découverte | Google trouve une URL via un lien, un sitemap ou un autre signal. | La page est connue, mais pas forcément visitée. |
| Crawl | Googlebot visite la page et récupère son contenu. | La page est accessible techniquement. |
| Indexation | Google décide d’ajouter ou non la page à son index. | La page peut potentiellement apparaître dans les résultats. |
| Classement | Google choisit où afficher la page selon une requête. | La page peut générer du trafic qualifié. |
Mon conseil : ne dites pas trop vite « Google n’a pas vu ma page ». Dans le cas « Explorée, actuellement non indexée », Google l’a vue. La vraie question est : pourquoi ne l’a-t-il pas retenue ?
Pourquoi Google explore une page sans l’indexer ?
Il n’existe pas une seule cause. C’est justement ce qui rend ce statut frustrant. Une page peut être explorée puis non indexée pour des raisons éditoriales, techniques, structurelles ou stratégiques.
1. Le contenu est trop faible ou trop générique
C’est le cas le plus fréquent. La page est accessible, propre techniquement, mais son contenu n’apporte pas assez de valeur.
Cela peut concerner :
- une page de service trop courte ;
- un article qui reformule ce que disent déjà dix concurrents ;
- une page locale créée en série ;
- une fiche produit qui reprend uniquement la description fournisseur ;
- un contenu assisté par IA sans expérience, sans exemple, sans point de vue ;
- une page qui répond mal à l’intention réelle de recherche.
Google recommande de créer des contenus utiles, fiables et pensés d’abord pour les utilisateurs. Cela ne veut pas dire écrire plus long pour écrire plus long. Cela veut dire apporter une réponse claire, originale, crédible et réellement utile.
Source officielle : Google Search Central — Créer du contenu utile, fiable et axé sur l’humain
2. La page ressemble trop à d’autres pages du site
Google n’a pas besoin d’indexer dix pages qui disent presque la même chose.
Je le vois souvent sur les sites locaux, les sites e-commerce et les sites qui ont voulu produire beaucoup de contenus très vite. On change le nom d’une ville, d’un modèle, d’un service ou d’une catégorie, mais le fond reste identique.
Quand dix pages disent presque la même chose avec seulement un mot qui change, Google peut très bien décider qu’une seule version suffit.
Exemples fréquents :
- pages locales générées sur le même modèle ;
- pages catégories e-commerce avec très peu de texte différenciant ;
- fiches produits quasi identiques ;
- articles de blog qui se recoupent trop fortement ;
- anciens contenus recyclés sans vrai nouvel angle.
3. Google choisit une autre URL canonique
Une page peut aussi ne pas être indexée parce que Google considère qu’une autre URL représente mieux le contenu.
Même si vous déclarez une URL canonique, Google peut parfois en choisir une autre. Cela arrive lorsque plusieurs pages sont trop proches, lorsque les signaux internes sont contradictoires ou lorsque la page déclarée canonique n’est pas celle qui paraît la plus pertinente aux yeux de Google.
Source officielle : Google Search Central — Résoudre les problèmes de canonicalisation
4. La page est trop profonde dans l’arborescence
Une page peut être techniquement accessible, mais très mal intégrée au site.
Si elle n’est liée depuis aucune page importante, si elle n’apparaît que dans le sitemap XML, ou si elle est enfouie dans une pagination, Google peut la considérer comme secondaire.
C’est là que le maillage interne devient essentiel. Une page importante doit recevoir des liens internes cohérents, depuis des pages elles-mêmes utiles et visibles.
5. Le site publie trop de contenus similaires
La production massive de contenus est devenue beaucoup plus simple avec l’IA. Mais ce n’est pas parce qu’un contenu peut être produit vite qu’il mérite forcément d’être indexé.
Google parle de scaled content abuse lorsque de nombreuses pages sont générées principalement pour manipuler les classements et non pour aider les utilisateurs. Le problème n’est pas uniquement l’IA. Le problème, c’est la production industrielle de contenus peu originaux, peu utiles ou trop proches les uns des autres.
Sources officielles : Google Search Central — Règles concernant le spam et Google Search Central — Utiliser du contenu généré par IA
| Cause possible | Symptôme observé | Correction prioritaire |
|---|---|---|
| Contenu faible | Page explorée mais non indexée depuis plusieurs semaines. | Réécrire, enrichir, ajouter des exemples, preuves et réponses concrètes. |
| Duplication interne | Plusieurs pages proches, une seule version retenue. | Fusionner, différencier ou canonicaliser. |
| Canonicalisation confuse | Google choisit une autre canonique. | Vérifier les balises canonical, liens internes, sitemaps et redirections. |
| Maillage faible | Page isolée ou très profonde. | Créer des liens depuis des pages fortes et pertinentes. |
| Publication massive | Grand nombre de pages similaires non indexées. | Nettoyer, prioriser, consolider et améliorer la valeur réelle. |
| Problème technique | Noindex, blocage robots.txt, redirection, erreur serveur. | Corriger les signaux techniques avant toute demande d’indexation. |
L’IA est-elle responsable des pages non indexées ?
Non, pas directement.
Une page n’est pas refusée parce qu’elle a été aidée par l’intelligence artificielle. Elle peut en revanche être ignorée si elle ressemble à des centaines d’autres pages, si elle n’apporte aucune expérience réelle, si elle reformule ce qui existe déjà partout, ou si elle a été publiée uniquement pour remplir un calendrier éditorial.
Je ne fais pas partie de ceux qui découvrent l’IA au détour d’un outil à la mode. L’IA peut être un outil formidable pour structurer une analyse, comparer des angles, accélérer une recherche, préparer un plan ou aider à reformuler. Mais elle devient dangereuse quand elle sert à publier cinquante pages moyennes au lieu d’en produire dix vraiment utiles.
Google indique que l’usage approprié de l’IA ou de l’automatisation n’est pas contraire à ses règles. En revanche, utiliser l’IA pour générer de nombreuses pages sans valeur ajoutée pour les utilisateurs peut entrer dans les pratiques abusives liées aux contenus produits à grande échelle.
Source officielle : Google Search Central — Contenus générés par IA
Mon conseil de vieux de la vieille : ne demandez pas seulement « est-ce que ce texte a été écrit avec l’IA ? ». Demandez plutôt : « est-ce que cette page apporte quelque chose que le client, le lecteur ou Google ne trouve pas déjà ailleurs ? ».
AI Overviews, AI Mode : pourquoi l’indexation reste essentielle
Depuis l’arrivée des réponses générées par IA dans Google Search, beaucoup d’entreprises se demandent comment apparaître dans les AI Overviews ou dans AI Mode.
C’est une vraie question. Mais il ne faut pas brûler les étapes.
Avant de vouloir être cité par l’IA de Google, il faut déjà que vos pages soient accessibles, compréhensibles, utiles et éligibles dans Google Search. Google rappelle que les bonnes pratiques SEO classiques restent pertinentes pour ses fonctionnalités IA : contenu utile, page techniquement accessible, expérience correcte, données structurées cohérentes avec le contenu visible.
Source officielle : Google Search Central — Fonctionnalités IA et votre site web
En mai 2025, Google a aussi publié des recommandations pour réussir dans la recherche IA. Le message reste très clair : les contenus uniques, utiles, fiables et agréables à consulter restent importants, aussi bien pour les résultats classiques que pour les expériences de recherche enrichies par l’IA.
Source officielle : Google Search Central Blog — Succeeding in AI Search
L’article de JC Chouinard sur les slides du Google Search Central Live Toronto d’avril 2026 va dans le même sens : avec l’IA, la barrière de production des contenus baisse fortement, ce qui pousse Google à relever son niveau d’exigence avant d’indexer. Son article rapporte aussi que le statut « Crawled — currently not indexed » est rarement seulement une question de rendu technique ; il peut refléter un sujet de qualité, de duplication, de canonicalisation ou d’autres problèmes techniques.
Source complémentaire : JC Chouinard — Google Search Central Live Toronto Slides, avril 2026
À retenir : on parle beaucoup de visibilité dans les réponses IA. C’est important. Mais une page qui n’entre pas dans l’index Google n’a déjà pas franchi le premier filtre.
Comment diagnostiquer une page explorée mais non indexée ?
Le mauvais réflexe consiste à cliquer tout de suite sur « Demander une indexation ».
Le bon réflexe consiste à comprendre pourquoi la page n’a pas été retenue.
| Étape | Question à poser | Outil recommandé |
|---|---|---|
| 1 | La page est-elle réellement absente de l’index ? | Google Search Console, commande site:, recherche exacte du titre |
| 2 | Google peut-il accéder à la page ? | Inspection d’URL dans Search Console |
| 3 | La page est-elle bloquée volontairement ou involontairement ? | robots.txt, balise meta robots, en-têtes HTTP |
| 4 | Google a-t-il choisi une autre URL canonique ? | Inspection d’URL, analyse canonical |
| 5 | Le contenu apporte-t-il une vraie valeur unique ? | Analyse éditoriale, comparaison SERP, audit de contenu |
| 6 | La page reçoit-elle des liens internes cohérents ? | Crawl du site, Screaming Frog, analyse du maillage |
| 7 | Googlebot passe-t-il réellement sur cette URL ? | Analyse des logs serveur |
Pour aller plus loin, l’analyse des fichiers journaux peut aider à vérifier le comportement réel de Googlebot. Search Console donne une vision utile, mais les logs serveur permettent de voir concrètement quelles URL sont explorées, à quelle fréquence, avec quel code de réponse et par quels robots.
À lire aussi : Analyse de fichiers journaux : l’outil SEO sous-estimé qui dit la vérité sur votre site
Source officielle : Google Search Central — Résoudre les problèmes d’exploration
Que faire pour corriger une page non indexée ?
La bonne correction dépend de la cause. Une page faible ne se corrige pas comme une page bloquée par une balise noindex. Une page dupliquée ne se corrige pas comme une page orpheline.
1. Renforcer le contenu
Si la page est trop faible, il faut la rendre plus utile.
Concrètement, vous pouvez :
- répondre plus clairement à l’intention de recherche ;
- ajouter des exemples métier ;
- intégrer des tableaux comparatifs ;
- ajouter une méthode ou une checklist ;
- citer des sources fiables ;
- ajouter une FAQ utile ;
- intégrer un retour d’expérience ;
- supprimer les paragraphes génériques ;
- différencier la page des autres contenus du site.
À lire aussi : Thin content : pourquoi vos pages ne cassent pas les classements et comment les réparer
2. Fusionner les pages trop proches
Il ne faut pas toujours chercher à sauver chaque URL.
Parfois, la meilleure décision SEO consiste à fusionner plusieurs contenus faibles en une page forte.
| Situation | Mauvais réflexe | Bonne approche |
|---|---|---|
| Trois articles proches sur le même sujet | Les garder séparés pour « avoir plus de pages » | Créer un guide complet, mieux structuré et mieux maillé |
| Dix pages locales quasi identiques | Changer seulement le nom de la ville | Différencier les pages ou réduire le nombre d’URL |
| Fiches produits très similaires | Indexer toutes les variantes | Choisir les pages utiles, canonicaliser ou enrichir les variantes fortes |
3. Améliorer le maillage interne
Une page importante doit être portée par le reste du site.
Si elle n’est liée nulle part, ou seulement depuis un sitemap XML, le signal envoyé à Google est faible. Une page stratégique doit être reliée depuis une page service, une page pilier, un article visible ou une rubrique pertinente.
Utilisez des ancres descriptives. Évitez les liens vagues du type « cliquez ici ». Préférez des ancres comme « audit SEO », « problème d’indexation Google », « maillage interne » ou « analyse des logs serveur ».
À lire aussi : Netlinking interne : les erreurs courantes qui ruinent vos efforts SEO
4. Corriger les signaux techniques
Avant de conclure que Google n’aime pas votre contenu, vérifiez les bases techniques.
- La page renvoie-t-elle un code HTTP 200 ?
- La page n’est-elle pas en noindex ?
- Le fichier robots.txt ne bloque-t-il pas l’exploration ?
- La balise canonical pointe-t-elle vers la bonne URL ?
- La page n’est-elle pas redirigée ?
- Le contenu principal est-il bien accessible sans dépendre uniquement de JavaScript ?
- La page est-elle présente dans le sitemap XML si elle est stratégique ?
- Le serveur répond-il correctement à Googlebot ?
À lire aussi : Les erreurs SEO techniques qui nuisent à votre référencement sans que vous le sachiez
5. Ne pas demander l’indexation sans avoir amélioré la page
Demander une indexation sans améliorer la page, c’est comme rappeler un client avec exactement le même devis qu’il vient de refuser. Parfois, ça passe. Souvent, ça ne change rien.
Avant de demander une nouvelle inspection dans Search Console, améliorez réellement la page : contenu, maillage, différenciation, signaux techniques, canonicalisation. Ensuite seulement, la demande d’indexation peut avoir du sens.
Faut-il supprimer les pages non indexées ?
Pas automatiquement.
Une page non indexée n’est pas forcément inutile. Certaines pages servent aux clients, au support, aux campagnes publicitaires, à la navigation ou à la conversion, sans avoir vocation à générer du trafic SEO.
En revanche, si une page devait capter du trafic organique et qu’elle reste durablement non indexée, il faut prendre une décision.
| Situation | Action recommandée |
|---|---|
| Page stratégique mais trop faible | Réécrire, enrichir, mieux mailler. |
| Page doublon ou très proche d’une autre | Fusionner, rediriger ou canonicaliser. |
| Page obsolète sans trafic ni utilité | Supprimer et rediriger si nécessaire. |
| Page utile pour les clients mais sans intérêt SEO | La garder, éventuellement en noindex si c’est cohérent. |
| Page générée automatiquement sans valeur | Supprimer, noindexer ou refondre complètement. |
| Page produit importante | Enrichir la fiche, ajouter du contenu unique, améliorer les liens internes. |
La bonne question est : cette URL mérite-t-elle encore d’exister dans une stratégie SEO ?
Ce que je regarde dans un audit SEO TooNetCreation
Dans un audit SEO, je ne regarde pas seulement si une page existe. Je regarde si elle mérite vraiment d’être indexée, si Google peut la comprendre, si elle répond à une intention claire, si elle reçoit des liens internes cohérents et si elle apporte quelque chose que les autres pages du site ne disent pas déjà.
Pour analyser un problème d’indexation, je regarde notamment :
- les rapports d’indexation dans Google Search Console ;
- les pages explorées mais non indexées ;
- les pages découvertes mais non explorées ;
- les erreurs noindex, robots.txt, 404, soft 404 ou redirections ;
- les canonicals déclarées et les canonicals choisies par Google ;
- la structure des URL ;
- les sitemaps XML ;
- le maillage interne ;
- les contenus trop proches ou trop faibles ;
- les gabarits de pages sur Joomla, WordPress, WooCommerce, PrestaShop ou autres CMS ;
- les logs serveur quand ils sont disponibles.
Ce diagnostic permet de distinguer trois familles de problèmes :
| Famille de problème | Exemples | Réponse SEO |
|---|---|---|
| Technique | Noindex, robots.txt, erreur serveur, redirection, canonical incohérente. | Corriger les blocages et clarifier les signaux. |
| Éditorial | Contenu faible, trop générique, trop proche d’autres pages. | Réécrire, enrichir, fusionner ou différencier. |
| Structurel | Page orpheline, arborescence confuse, maillage insuffisant. | Repenser la place de la page dans le site. |
C’est aussi pour cela que l’audit digital ne doit pas être limité à une liste d’erreurs techniques. Un site peut être techniquement propre et pourtant publier des contenus que Google ne juge pas assez utiles pour son index.
Si le sujet touche aussi aux réponses générées par IA, il peut être utile de compléter l’analyse avec un audit de visibilité IA, mais seulement après avoir vérifié les fondations : indexation, qualité, maillage et autorité.
Lectures complémentaires sur le blog TooNetCreation
Pour approfondir ce sujet, vous pouvez compléter votre lecture avec ces articles :
- Utiliser la Search Console pour améliorer réellement son SEO
- Crawl budget : les fondamentaux
- Thin content : pourquoi vos pages ne cassent pas les classements
- Google pénalise-t-il le contenu IA ?
- GEO : préparer son contenu aux moteurs de recherche IA
- Refonte SEO : redirections, sitemaps et points de vigilance
- Notre accompagnement en référencement naturel SEO
Que retenir ? publier plus ne suffit plus
Une page explorée mais non indexée n’est pas forcément une page perdue. C’est souvent une page qui demande à être mieux pensée, mieux reliée, mieux différenciée ou mieux justifiée.
Avec l’IA, produire du contenu est devenu plus rapide. Mais la rapidité de production ne crée pas automatiquement de la valeur. Google n’a pas besoin d’un web rempli de pages interchangeables. Il cherche à retenir les contenus capables d’aider réellement les utilisateurs.
Pour une PME, un e-commerçant ou une organisation qui investit dans son site, le message est simple : avant de publier encore plus, regardez déjà ce que Google refuse d’indexer. Ces pages racontent souvent une histoire très claire sur la qualité du contenu, la structure du site, le maillage interne et la stratégie éditoriale.
Le SEO de 2026 ne consiste pas à produire toujours plus de pages. Il consiste à produire les bonnes pages, au bon endroit, avec une vraie valeur, une structure claire et des signaux cohérents.
Vous avez des pages importantes qui restent non indexées dans Google Search Console ? TooNetCreation peut analyser vos contenus, votre maillage interne, vos données Search Console, vos logs serveur et vos signaux techniques pour identifier les vraies causes du problème.
FAQ : pages explorées mais non indexées
Une page explorée mais non indexée peut-elle finir par être indexée ?
Oui, c’est possible. Mais si la situation dure ou concerne des pages importantes, il faut analyser la qualité du contenu, la duplication, la canonicalisation, le maillage interne et les éventuels blocages techniques.
Faut-il demander une indexation dans Search Console ?
Oui, mais seulement après avoir corrigé ou amélioré la page. Demander une indexation sans changement réel donne rarement de bons résultats durables.
Est-ce que Google refuse les contenus écrits avec l’IA ?
Non. Google ne refuse pas un contenu parce qu’il a été aidé par l’IA. Il refuse ou ignore surtout les contenus peu utiles, trop similaires, générés en masse ou créés principalement pour manipuler les classements.
Une page non indexée nuit-elle au SEO du site ?
Pas toujours. Certaines pages n’ont pas vocation à être indexées. Le problème apparaît quand des pages stratégiques, commerciales ou éditoriales restent durablement exclues de l’index.
Une page présente dans le sitemap XML doit-elle forcément être indexée ?
Non. Le sitemap aide Google à découvrir les URL importantes, mais il ne garantit pas leur indexation. La page doit aussi être accessible, utile, cohérente et suffisamment différenciante.
Le problème vient-il toujours du contenu ?
Non. Le contenu est une cause fréquente, mais il faut aussi vérifier les signaux techniques : noindex, robots.txt, canonical, redirections, erreurs serveur, profondeur de clics et maillage interne.
Sources et références
- Google Search Console — Rapport d’indexation des pages
- Google Search Central — Fonctionnement de la recherche Google
- Google Search Central — Créer du contenu utile, fiable et axé sur l’humain
- Google Search Central — Utiliser du contenu généré par IA
- Google Search Central — Règles concernant le spam
- Google Search Central — Fonctionnalités IA et votre site web
- Google Search Central — Résoudre les problèmes de canonicalisation
- Google Search Central — Résoudre les problèmes d’exploration
- Google Search Central Blog — Succeeding in AI Search
- JC Chouinard — Google Search Central Live Toronto Slides, avril 2026



